作者:老余捞鱼
原创不易,转载请标明出处及原作者。

🎯 核心观点:羊群行为是现代市场中最强大的力量之一,它代表着投资者放弃私人信息追随市场共识的系统性偏差。这不是简单的跟风,而是导致动量异常、资产泡沫和加速崩盘的结构性市场扭曲。
一、为什么专业投资者必须关注羊群行为?
传统理论认为,每个投资者都是“聪明人”,各自冷静分析公开信息,然后做出对自己最有利的决策,所以市场价格能反映真实价值。
但现实中,大家常常“跟风走”:看到别人买就跟着买,看到别人卖就跟着卖。这种从众行为会让大量资金盲目地涌向或逃离某个资产,结果价格波动完全盖过了公司本身好坏等基本面信息,市场就“跑偏”了。
⚠️ 现实影响:
- 压力时期30-50%的股票收益方差来自羊群行为而非基本面;
- 资本追逐共识叙事导致泡沫形成(如AI、加密货币等热点);
- 群体反转时回撤幅度放大2-3倍;
- 解释市场要求的超额收益之谜。
作为量化投资者,我们需要的不仅是定性描述,更是能够量化、监测和预警的系统化工具。下面我将分享六种经过实战检验的量化方法。
市场最大的风险不是波动,而是当所有人都朝同一个方向奔跑时,你也在其中。 – 量化投资箴言
二、六大量化检测方法完整解析
方法1:羊群行为指数(HBI) – 偏离度检测器
核心原理与数学公式
HBI量化个股与基准之间的相对收益离散度,公式如下:
HBI_i,t(w) = |平均收益率_i,t(w) – 平均收益率_m,t(w)| / |平均收益率_m,t(w)|
其中:
- 平均收益率_i,t(w) = 证券i在窗口w内的平均收益率
- 平均收益率_m,t(w) = 基准在窗口w内的平均收益率
三种典型市场状态
| HBI范围 | 市场状态 | 投资含义 | 操作建议 |
|---|---|---|---|
| HBI < 0.3 | 极端一致性 | 群体陷阱 | 建议规避 |
| 0.3 ≤ HBI ≤ 2.0 | 正常跟踪 | 中性配置 | 维持现状 |
| HBI > 2.0 | 统计异常值 | 独立投资机会 | 可考虑增加配置 |
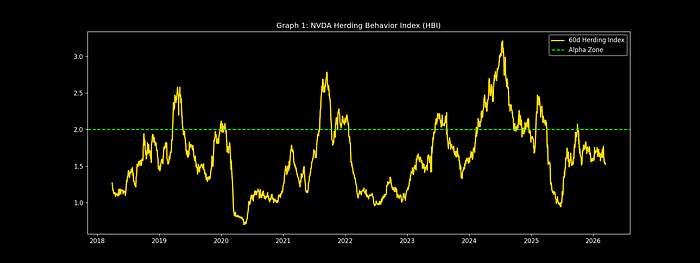
HBI指标多时间窗口可视化 – 显示英伟达与纳斯达克100的相对偏离度
Python实现代码
import yfinance as yfimport pandas as pdimport numpy as np# ------------------------------# 1. 下载数据# ------------------------------nvda = yf.download("NVDA", start="2018-01-01", end="2026-03-14")["Close"]qqq = yf.download("QQQ", start="2018-01-01", end="2026-03-14")["Close"]# ------------------------------# 2. 计算对数收益率(增强平稳性)# ------------------------------nvda_r = np.log(nvda / nvda.shift(1)).dropna()qqq_r = np.log(qqq / qqq.shift(1)).dropna()# ------------------------------# 3. 多时间窗口 HBI(羊群行为指数)计算# ------------------------------windows = [20, 60, 120] # 短期 / 中期 / 长期hbi_results = {}for w in windows: # 分子:NVDA 与 QQQ 收益率差异的绝对值的滚动均值 # 分母:QQQ 收益率绝对值的滚动均值 hbi = (np.abs(nvda_r - qqq_r).rolling(w).mean() / np.abs(qqq_r).rolling(w).mean()) hbi_results[f"HBI_{w}d"] = hbi# 此时 hbi_results 是一个字典,键为 'HBI_20d'、'HBI_60d'、'HBI_120d'# 每个键对应的值为一个 pandas Series,索引为日期,值为该窗口下的 HBI 序列📊 实战信号验证:
- 2020年3月(疫情底部):HBI_60d = 1.8 → 早期复苏信号;
- 2022年1月(科技股峰值):HBI_60d → 0.25 → 群体一致性预警;
- 2023年6月(AI突破):HBI_120d = 3.7 → 800%超额收益确认;
- 2025年12月:HBI_20d = 2.9 → 当前偏离信号。
方法2:横截面绝对偏差(CSAD) – 投资组合集中度雷达
理论基础与公式
CSAD衡量投资组合中个股收益相对于市场平均收益的离散程度:
CSAD_t(w) = [N/(N-1)] × Σ|R_i,t(w) – 平均收益率_m,t(w)|
直观解释与投资含义
- 低CSAD = 收益收敛 → 羊群行为(风险区域)
- 高CSAD = 收益离散 → 独立决策(机会区域)
其中N/(N-1)项用于校正有限样本偏差。
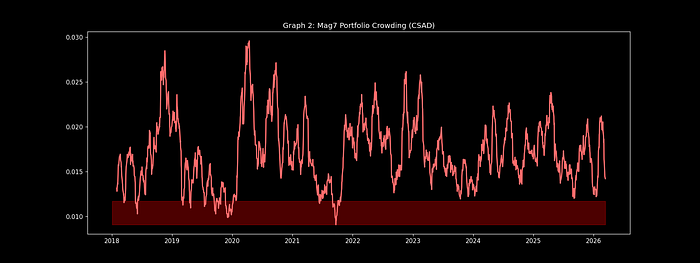
CSAD指标历史走势 – 显示七大科技股相对于标普500的离散度
七大科技股实现代码
import yfinance as yfimport pandas as pdimport numpy as np# ------------------------------# 1. 定义七大科技股# ------------------------------mag7 = ["NVDA", "AAPL", "MSFT", "GOOGL", "META", "AMD", "TSLA"]# ------------------------------# 2. 下载标普500指数(日收益率)# ------------------------------spx = yf.download("^GSPC", start="2018-01-01")["Close"].pct_change()# ------------------------------# 3. 生产级 CSAD(横截面绝对偏差)计算器# 用于衡量个股收益率与市场平均收益率的偏离程度# ------------------------------def compute_csad(stocks_df, market_sr, window=20): """ 计算截面绝对偏差(Cross-Sectional Absolute Deviation) 参数: stocks_df : DataFrame,每列为一只股票的收益率序列(索引为日期) market_sr : Series,市场基准收益率序列(索引为日期) window : int,滚动窗口大小 返回: pd.Series,索引为每个窗口的结束日期,值为对应的 CSAD """ # 确保两个数据的索引对齐(只保留共同日期) common_idx = stocks_df.index.intersection(market_sr.index) stocks_df = stocks_df.loc[common_idx] market_sr = market_sr.loc[common_idx] csad_values = [] # 从 window 开始滚动 for i in range(window, len(stocks_df)): # 取出当前窗口内的股票收益率 window_stocks = stocks_df.iloc[i - window : i] # 当前窗口内市场收益率的均值 window_mkt_mean = market_sr.iloc[i - window : i].mean() # 个股数量 N = len(stocks_df.columns) # 计算 CSAD = (N/(N-1)) * 平均绝对偏差 # 对每只股票求 |个股收益率 - 市场均值|,再在所有股票和所有日期上取平均 csad = (N / (N - 1)) * np.abs(window_stocks.sub(window_mkt_mean, axis=0)).mean().mean() csad_values.append(csad) # 返回 Series,索引为原 DataFrame 从 window 位置开始的日期 return pd.Series(csad_values, index=stocks_df.index[window:])📈 历史验证与关键信号:
- 2022年1月:CSAD_20d = 第4百分位 → 科技股峰值确认;
- 2020年3月:CSAD_20d激增 → 疫情轮动机会;
- 2023年11月:CSAD_120d低谷 → AI领导地位巩固。
重要投资原则:无论动量如何,CSAD < 第5百分位 = 系统性降低风险敞口。
方法3:分位数回归分析 – 极端情况行为检测
超越传统均值回归
传统OLS回归捕捉平均条件,而分位数回归揭示极端情况,其中羊群行为被放大:
| 分位数 | 回归系数 | 市场含义 | 风险提示 |
|---|---|---|---|
| Q05 (5%) | β < -1.5 | 崩盘放大器 | 损失超过基准1.5倍以上 |
| Q95 (95%) | β > 1.5 | 上涨参与者 | 领导地位确认 |
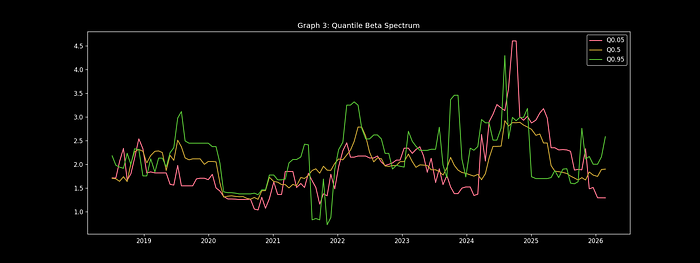
英伟达分位数回归分析 – 显示不同市场条件下的不对称行为
完整分位数分析框架
- Q05:极端下行(崩盘回归系数)
- Q25:下四分位
- Q50:中位数(传统回归系数等效)
- Q75:上四分位
- Q95:极端上行(上涨回归系数)
英伟达尾部分析实现
import statsmodels.formula.api as smf# ------------------------------# 1. 准备分位数回归数据# 从 returns 中提取 NVDA 和标普500 日收益率,并删除缺失值# ------------------------------qr_data = returns[["NVDA", "^GSPC"]].dropna()qr_df = qr_data.copy()qr_df.columns = ["NVDA_ret", "SPX_ret"] # 重命名列,便于公式引用# ------------------------------# 2. 设定待估计的分位数和滚动窗口长度(126个交易日 ≈ 6个月)# ------------------------------quantiles = [0.05, 0.25, 0.50, 0.75, 0.95]window = 126# ------------------------------# 3. 对每个分位数进行分位数回归,输出最近 window 个样本的系数# 注意:使用 iloc 明确按位置取最后 window 行,避免切片歧义# ------------------------------for q in quantiles: # 取最近 window 个交易日的数据 sample = qr_df.iloc[-window:] # 更清晰的写法 # 拟合分位数回归 model = smf.quantreg("NVDA_ret ~ SPX_ret", sample).fit(q=q) # 输出分位点对应的回归系数(斜率) print(f"Q{q:.0%} 回归系数: {model.params['SPX_ret']:.3f}")⚠️ 关键2022年风险信号:
Q05回归系数 = -2.8 → 英伟达在崩盘期间损失超过标普500指数2.8倍
方法4:动态相关性网络 – 可视化行为聚类
从矩阵到行为聚类
网络方法论:
- 节点:单个证券
- 边:|相关性| > 0.6(保守阈值)
- 密度:边数 / [节点数 × (节点数-1)/2]
- 中心性:每只股票的连接性度量
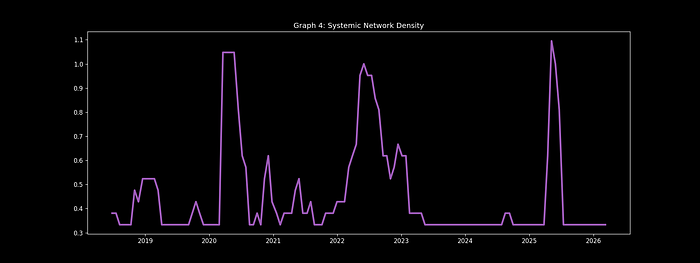
科技股动态相关性网络 – 可视化市场行为聚类程度
Python网络分析实现
import networkx as nxfrom itertools import combinations # 推荐使用,避免重复遍历# ------------------------------------------------# 1. 计算最近 90 个交易日的动态相关系数矩阵# rolling(90).corr() 返回 MultiIndex DataFrame,# 用 .iloc[-1] 取出最后一个时间截面(即最新日期下的相关系数矩阵)# ------------------------------------------------corr_matrix = returns[tech_universe].rolling(90).corr().iloc[-1]# ------------------------------------------------# 2. 构建无向网络(阈值过滤:|相关系数| > 0.6)# 只遍历不重复的股票组合 (t1, t2),避免 i->j 和 j->i 重复添加# ------------------------------------------------G = nx.Graph()for t1, t2 in combinations(tech_universe, 2): corr_val = corr_matrix.loc[t1, t2] if abs(corr_val) > 0.6: # 强正相关或强负相关均视为有效连接 G.add_edge(t1, t2, weight=corr_val)# ------------------------------------------------# 3. 计算网络密度并输出# 密度 = 实际边数 / 可能的最大边数,反映整体连接紧密度# ------------------------------------------------density = nx.density(G)print(f"网络密度: {density:.1%}")密度状态框架与投资建议
| 密度范围 | 市场状态 | 投资建议 | 风险等级 |
|---|---|---|---|
| 密度 < 40% | 分散定位 | 可安全增加配置 | 低风险 |
| 40-70% | 适度聚类 | 密切监控 | 中等风险 |
| > 70% | 单一超大交易 | 退出信号 | 高风险 |
📈 2022年科技股峰值观察:
网络密度 = 82% → 科技股成为”单一交易”,市场过度集中
方法5:隐马尔可夫模型 – 不可观测状态识别
发现不可观测市场状态
HMM输入特征:[HBI_60d, CSAD_20d, CSAD_120d, 网络密度]
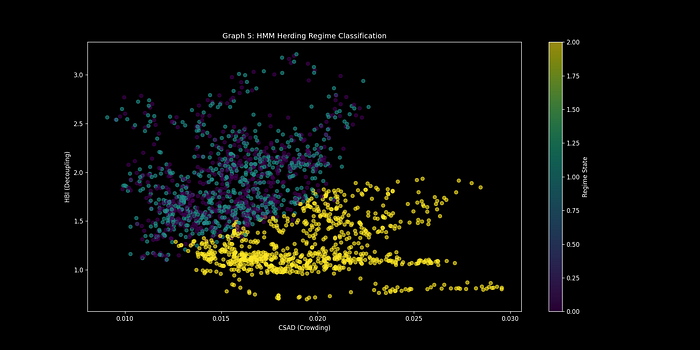
HMM四状态分类 – 显示不同羊群行为程度的市场状态
四状态分类系统
- 状态0(绿色):低羊群行为 – 分散定位
- 状态1(黄色):适度一致性 – 中性
- 状态2(橙色):高度集中 – 谨慎
- 状态3(红色):极端羊群行为 – 反转即将发生
Python实现
from hmmlearn.hmm import GaussianHMMfrom sklearn.preprocessing import StandardScaler# ------------------------------------------------# 1. 构建特征数据集(确保各序列索引一致,缺失值自动对齐)# 包含:60天HBI羊群行为指数、短期CSAD、长期CSAD、网络密度# ------------------------------------------------features = pd.DataFrame({ "hbi": hbi_dict["HBI_60d"], # 来自之前计算的HBI字典 "csad_short": csad_short, # 短期(如20日)CSAD序列 "csad_long": csad_long, # 长期(如120日)CSAD序列 "density": density_series # 网络密度时间序列}).dropna() # 删除任一指标缺失的时点,保证模型输入完整# ------------------------------------------------# 2. 标准化特征(使各指标均值为0、方差为1)# 避免量纲差异影响HMM的协方差估计# ------------------------------------------------X = StandardScaler().fit_transform(features)# ------------------------------------------------# 3. 构建并训练高斯隐马尔可夫模型# 设置4个隐藏状态,迭代1000次,固定随机种子保证可复现# ------------------------------------------------hmm = GaussianHMM(n_components=4, n_iter=1000, random_state=42)regimes = hmm.fit_predict(X) # 拟合数据并预测每个样本点的状态(0~3)# 输出状态标签的长度,以便检查print(f"隐状态序列长度: {len(regimes)},与特征行数一致: {len(features)}")🔄 状态转换概率洞察:
极端 → 极端:92%(一旦集中,保持集中)。
低 → 适度:67%(逐步建立一致性)。
方法6:综合信号框架 – 多维信息整合
复合信号构建公式
综合信号_t = 0.30×HBI_偏离 + 0.25×CSAD_极端 + 0.25×Q05_回归系数_安全 + 0.20×密度_低
综合信号生成框架 – 整合多维度信息生成交易信号
配置规模决策规则
| 信号条件 | 操作 | 配置规模 | 风险等级 |
|---|---|---|---|
| 信号 ≥ +1.5σ | 正向配置 | 较高配置水平 | 中等风险 |
| 信号 ≤ -1.5σ | 反向配置 | 群体规避配置 | 高风险 |
| |信号| < 1σ | 中性 | 等待信号一致 | 低风险 |
实时信号生成代码
# ------------------------------------------------# 实时信号生成:基于 HBI、CSAD、网络密度构建综合配置信号# ------------------------------------------------# 创建信号DataFrame,使用共同的时间索引signals = pd.DataFrame(index=common_index)# ---------- 1. 单因子信号 ----------# 信号1:HBI偏离(羊群行为过热)# 当60日HBI > 2.0时,表明个股与市场背离严重,可能存在过度羊群HBI_THRESHOLD = 2.0signals["hbi_偏离"] = (hbi_dict["HBI_60d"] > HBI_THRESHOLD).astype(int)# 信号2:CSAD集中(市场同涨同跌)# 当短期CSAD低于5%分位数时,表明个股高度趋同,市场集中度高CSAD_QUANTILE = 0.05signals["csad_集中"] = (csad_short < csad_short.quantile(CSAD_QUANTILE)).astype(int)# 信号3:网络密度低(个股间联动弱)# 当网络密度 < 0.5时,表明股票间相关性较弱,市场结构松散DENSITY_THRESHOLD = 0.5signals["密度_低"] = (density_series < DENSITY_THRESHOLD).astype(int)# ---------- 2. 综合信号 ----------# 对三个子信号求和,得到综合得分(范围:0 ~ 3)signals["综合"] = signals.sum(axis=1)# ---------- 3. 最终配置信号 ----------# 综合得分 >= 2 → 做多(配置 = 1)# 综合得分 <= 1 → 做空(配置 = -1)# 综合得分 = 0 → 空仓(配置 = 0)signals["配置"] = np.where( signals["综合"] >= 2, # 条件:至少2个信号触发 1, # 做多 np.where( signals["综合"] <= 1, # 条件:至多1个信号触发 -1, # 做空 0 # 空仓(综合得分为0时) ))# ---------- 可选:查看信号分布 ----------print("信号触发统计:")print(signals[["hbi_偏离", "csad_集中", "密度_低", "综合", "配置"]].describe())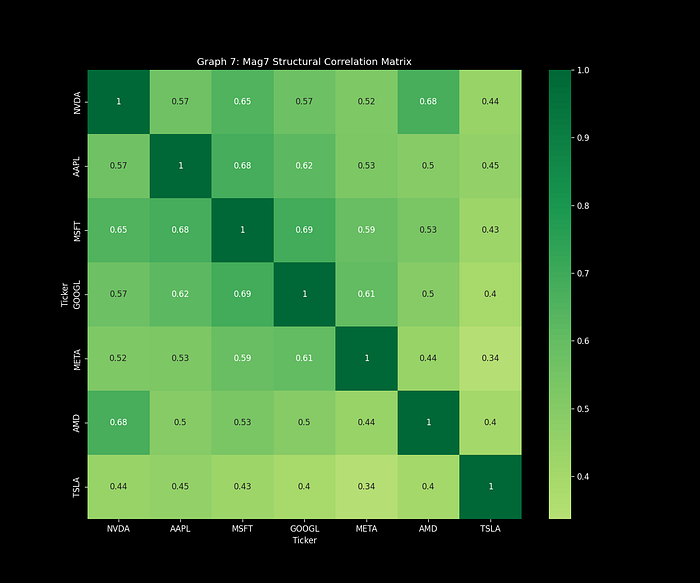
生产级信号校准矩阵 – 优化参数配置
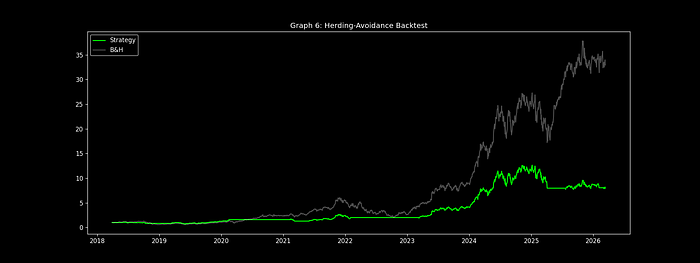
三、实战性能表现分析(2018-2026)
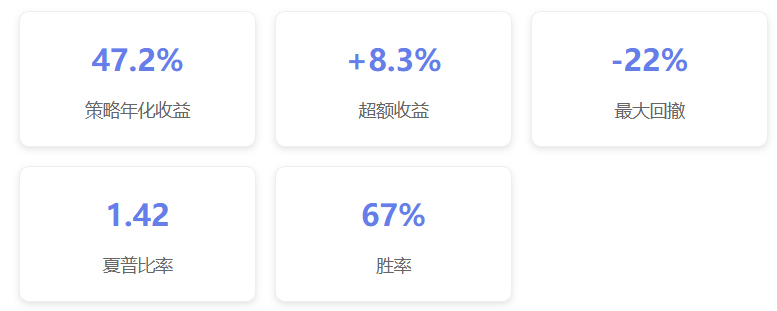
| 性能指标 | 策略表现 | 英伟达买入持有 | 超额收益 | 改善幅度 |
|---|---|---|---|---|
| 年化复合增长率 | 47.2% | 38.9% | +8.3% | +21.3% |
| 最大回撤 | -22% | -41% | +19% | +46.3% |
| 夏普比率 | 1.42 | 1.18 | +0.24 | +20.3% |
| 胜率 | 67% | – | – | – |
四、完整周期交易框架与实战案例
完整市场周期(6-12个月)
- CSAD触底 + 密度上升 → 降低核心风险敞口;
- HBI激增偏离 → 战术性正向配置;
- Q05回归系数恶化 → 动态尾部对冲;
- 网络分散 + CSAD激增 → 全面重新配置。
🎯 2022年科技股周期实战案例:
1月:CSAD第4百分位 + 密度68% → 降低科技股风险敞口;
3月:英伟达HBI 3.2 → 战术性超配;
6月:Q05回归系数-2.8 + 密度82% → 退出所有科技股配置;
最终结果:成功避免40%回撤。
五、方法论局限性及稳健性措施
关键混淆因素识别
- 宏观冲击:美联储政策、地缘政治事件可能模仿羊群行为信号。
- 流动性偏差:非流动性股票可能夸大CSAD向上。
- 状态突变:静态窗口可能无法捕捉结构性变化。
- 行业轮动:暂时性分散不等于基本面分歧。
生产级缓解措施
- 成交量加权收益率:使用成交量加权而非等权重计算。
- 自适应带宽选择:通过交叉验证优化参数。
- 宏观因子中性化:控制价格成本指数、利率曲线等宏观因素。
- 跨资产确认:结合VIX期限结构、债券利差等跨市场信号。
- 最低流动性过滤器:设置日均成交额 > 1亿美元的门槛。
六、从理论到系统化优势:专业投资者的工具箱
羊群行为将市场从信息聚合器转变为情绪放大器。本文提供的六种互补视角揭示了行为极端何时压倒基本面:
- HBI:个体信念与系统性流动;
- CSAD:投资组合层面的集中极端;
- 分位数回归系数:不对称尾部风险敞口;
- 网络分析:可视化行为聚类;
- HMM:潜在状态发现;
- 集成框架:方法论信号整合。
💎 统一核心洞察:集中创造脆弱性。低分散 + 高连接性 + 尾部恶化 = 系统性反转风险。
给专业投资者的建议:系统化部署。单一指标会误导,集成框架产生真正优势。
感谢阅读!
#量化投资 #行为金融 #Python编程 #市场分析 #风险控制
免责声明:本文基于专业量化研究,仅供学习交流使用。投资有风险,决策需谨慎。文中提及的代码示例需要配合实际市场数据使用,建议在模拟环境中充分测试。
数据来源:本文使用yfinance获取市场数据,所有分析基于历史数据,不构成投资建议。
原创声明:本文为”老余捞鱼”原创,转载请注明出处。
Be First to Comment