作 者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:做了多年量化,踩过无数坑。今天我把均线交叉策略最核心的东西掏出来:SMA、EMA、WMA这三种算法怎么选?短期和长期参数到底怎么配?信号准确率怎么算?这篇文章不讲虚的,代码直接给,逻辑掰开揉碎讲清楚。
很多人第一次接触技术分析,学的第一个工具就是均线。说实话,均线是所有技术指标里最不起眼的那个:它既没有MACD那么花哨,也没有RSI那样自带超买超卖的神秘光环。但就是这个看起来”平平无奇”的东西,支撑了我多年量化策略里至少一半的信号逻辑。
今天这篇文章,我想把均线交叉策略这件事从头到尾说清楚:不同的均线方法有什么区别?短周期和长周期怎么搭配才靠谱?信号出来的准确率到底怎么算?代码全部附上,你看完就能跑。
① 均线交叉信号,到底在说什么?
我先不急着上代码,而是想把这个信号背后的逻辑聊透。
假设你手里有一只标的,你想知道它最近是偏强还是偏弱。一个很本能的做法就是:看看最近一段时间的平均价格,跟更长时间的平均价格比一比。如果近期的均价跑到长期均价上面去了,说明最近的市场情绪偏积极;反过来,如果近期均价掉到长期均价下面,说明市场情绪在转冷。
这就是均线交叉最基本的思想:用两条不同时间窗口的平均价格曲线的相对位置,来判断趋势的方向性变化。
在量化圈子里,我们通常把这种交叉分成两种场景:
- 短期均线上穿长期均线:短期价格走势强于长期趋势,通常被视为一个趋势转强的信号。如果你看到”Golden Cross”这个词,指的就是这个。我们在国内语境下叫它”交叉转强信号”。
- 短期均线下穿长期均线:短期价格走势弱于长期趋势,通常被视为趋势转弱的信号。对应的英文叫”Death Cross”,我们叫”交叉转弱信号”。
和卖出(死亡交叉)信号的可视化-1024x439.webp)
【图1】交叉转强信号与交叉转弱信号在价格走势中的可视化示意
道理很简单,但真正的问题是:你用什么方法算均线?不同的算法,得到的交叉点可能完全不一样。下面我们就来拆开讲。
② 三种均线方法各有千秋
很多人一上来就把SMA、EMA、WMA这些词混在一起,觉得反正都是”平均”,差不多就行。这个想法会害死人的。三种方法背后是完全不同的数学逻辑,搞不清楚区别,策略回测出来的结果就毫无意义。
1. 简单移动平均(SMA)
SMA是最老实的算法:把过去N天的价格加起来,除以N。每一天的权重完全一样,不论它是昨天还是三个月前。公式如下:
SMA = \frac{P_1 + P_2 + \dots + P_n}{n}
SMA的优点是稳定,缺点也很明显——它对最近发生的事情和很久以前发生的事情一视同仁,导致信号反应偏慢。在趋势明确的行情中这不是问题,但在快速变化的波动行情里,SMA可能会让你慢半拍。
2. 指数移动平均(EMA)
EMA跟SMA最大的不同是:它给近期的价格更大的权重。算法上,EMA采用递推方式计算,今天的EMA值等于昨天EMA加上今日价格与昨日EMA差值的一个比例。这不是简单平均,而是一种衰减加权——越久远的数据,影响力越低。
EMA对价格变化更敏感,信号出得比SMA快,适合那些对时效性要求比较高的策略场景。但敏感也意味着噪音多,虚假信号的概率会上升。
3. 加权移动平均(WMA)
WMA也是给不同时间点赋不同权重,但它的做法跟EMA不一样:WMA直接给每天的收盘价乘以一个线性递减的系数,最近一天乘最大,倒数第二天乘次大,以此类推。公式如下:
WMA = \frac{n \cdot P_1 + (n-1) \cdot P_2 + \dots + 1 \cdot P_n}{n + (n-1) + \dots + 1}
WMA更像是一个折中方案,比SMA灵敏,但没有EMA那么激进。它最大的价值在于突出关键价格区间,特别是当你在某个特定的时间窗口内有明确的关注重点时。
下面这张表帮你快速对比三者的差异:
| 特性 | SMA | EMA | WMA |
|---|---|---|---|
| 权重分配 | 等权 | 指数衰减 | 线性递减 |
| 响应速度 | 慢 | 快 | 中等 |
| 信号噪音 | 低 | 较高 | 中等 |
| 适用场景 | 中长期趋势 | 短中期波动 | 关键区间分析 |
| 计算复杂度 | 低 | 中等 | 中等 |
③ Python实战:三种均线一把抓
光说不练假把式。下面这段代码,我用的是 yfinance 拉数据,pandas 做计算,matplotlib 画图。三个函数分别对应SMA、EMA、WMA,参数清晰,拿来就能用。
import yfinance as yfimport matplotlib.pyplot as pltimport pandas as pdimport numpy as np# ======== 1. 获取数据 ========def fetch_data(stock_symbol, start_date, end_date): """ 从Yahoo Finance拉取历史行情数据 参数: stock_symbol: 标的代码,如 'AAPL' start_date: 起始日期 '2020-01-01' end_date: 截止日期 '2024-01-01' 返回: pandas DataFrame,含OHLCV数据 """ data = yf.download(stock_symbol, start=start_date, end=end_date) return data# ======== 2. 三种均线函数 ========def SMA(data, window): """简单移动平均:过去window天的收盘价算术平均""" return data.rolling(window=window).mean()def EMA(data, window): """指数移动平均:近期价格权重更高,使用ewm实现""" return data.ewm(span=window, adjust=False).mean()def WMA(data, window): """加权移动平均:线性递减权重,最近一天权值最大""" weights = np.arange(1, window + 1) return data.rolling(window=window).apply( lambda prices: np.dot(prices, weights[::-1]) / weights.sum(), raw=True )# ======== 3. 信号识别 ========def identify_signals(data, short_window, long_window, ma_function): """ 识别均线交叉信号 逻辑:短期均线 > 长期均线 → 标记为1(偏强) 短期均线 < 长期均线 → 标记为0(偏弱) Position列记录了信号的变化点(1为转强,-1为转弱) """ data['Short_MA'] = ma_function(data['Close'], short_window) data['Long_MA'] = ma_function(data['Close'], long_window) data['Signal'] = 0 data['Signal'] = np.where(data['Short_MA'] > data['Long_MA'], 1.0, 0.0) data['Positions'] = data['Signal'].diff() return data# ======== 4. 准确率计算 ========def calculate_accuracy(data, look_forward=5): """ 计算信号的准确率 方法:看向前N天的价格方向是否与信号方向一致 - 转强信号出现后,如果未来N天价格上涨 → 信号有效 - 转弱信号出现后,如果未来N天价格下跌 → 信号有效 """ data['Future_Close'] = data['Close'].shift(-look_forward) # 转强信号:当天价格 < 未来价格 → 正确 buys = data[(data['Positions'] == 1) & (data['Close'] < data['Future_Close'])] # 转弱信号:当天价格 > 未来价格 → 正确 sells = data[(data['Positions'] == -1) & (data['Close'] > data['Future_Close'])] buy_acc = len(buys) / len(data[data['Positions'] == 1]) \ if len(data[data['Positions'] == 1]) > 0 else np.nan sell_acc = len(sells) / len(data[data['Positions'] == -1]) \ if len(data[data['Positions'] == -1]) > 0 else np.nan return buy_acc, sell_acc# ======== 5. 可视化 ========def plot_ma_signals(stock_data, combinations, ma_function, ma_label): """ 绘制不同时间参数组合下的均线交叉信号图 6个子图,分别对应6组(短周期,长周期)组合 每个子图显示:价格曲线、短/长期均线、转强/转弱信号点、准确率 """ fig, axs = plt.subplots(3, 2, figsize=(25, 15)) fig.suptitle(f'{ma_label} 不同时间尺度下的交叉信号对比', fontsize=16) term_labels = { (5, 20): "短期 (5/20天)", (10, 50): "短中期 (10/50天)", (20, 100): "中期 (20/100天)", (50, 200): "中长期 (50/200天)", (100, 250): "长期 (100/250天)", (200, 365): "超长期 (200/365天)" } for i, (short_window, long_window) in enumerate(combinations, 1): data = identify_signals(stock_data.copy(), short_window, long_window, ma_function) buy_accuracy, sell_accuracy = calculate_accuracy(data) term_label = term_labels.get((short_window, long_window), f"{short_window}/{long_window}") ax = axs[(i - 1) // 2, (i - 1) % 2] ax.plot(data.index, data['Close'], label='收盘价', alpha=0.5) ax.plot(data.index, data['Short_MA'], label=f'{short_window}天{ma_label}', alpha=0.8) ax.plot(data.index, data['Long_MA'], label=f'{long_window}天{ma_label}', alpha=0.8) # 转强信号:绿色三角 ax.scatter(data.index, data['Close'], label='转强信号', marker='^', color='g', alpha=1, s=50 * data['Positions'].clip(lower=0)) # 转弱信号:红色倒三角 ax.scatter(data.index, data['Close'], label='转弱信号', marker='v', color='r', alpha=1, s=50 * data['Positions'].clip(upper=0).abs()) accuracy_title = f"转强准确率: {buy_accuracy*100:.0f}%, 转弱准确率: {sell_accuracy*100:.0f}%" ax.set_title(f'{term_label} {ma_label} 交叉 - {accuracy_title}') ax.set_xlabel('日期') ax.set_ylabel('价格') ax.legend() plt.tight_layout(rect=[0, 0, 1, 0.96]) plt.show()# ======== 6. 主程序 ========stock = 'AAPL'start_date = '2020-01-01'end_date = '2024-01-01'# 六组参数,覆盖从短期到超长期time_scale_combinations = [(5, 20), (10, 50), (20, 100), (50, 200), (100, 250), (200, 365)]stock_data = fetch_data(stock, start_date, end_date)# 分别用SMA、EMA、WMA跑一遍plot_ma_signals(stock_data, time_scale_combinations, SMA, "SMA")plot_ma_signals(stock_data, time_scale_combinations, EMA, "EMA")plot_ma_signals(stock_data, time_scale_combinations, WMA, "WMA")上面这段代码的完整可运行版本和更详细的参数说明,这里展示的是核心逻辑,砍掉了一些辅助函数,保证你拿到就能理解主干。
如果大家需要深入学习了解,可以看看我前面写过的一篇文章:掌握这5种专家级MA(移动平均线)技术,让您的交易如鱼得水
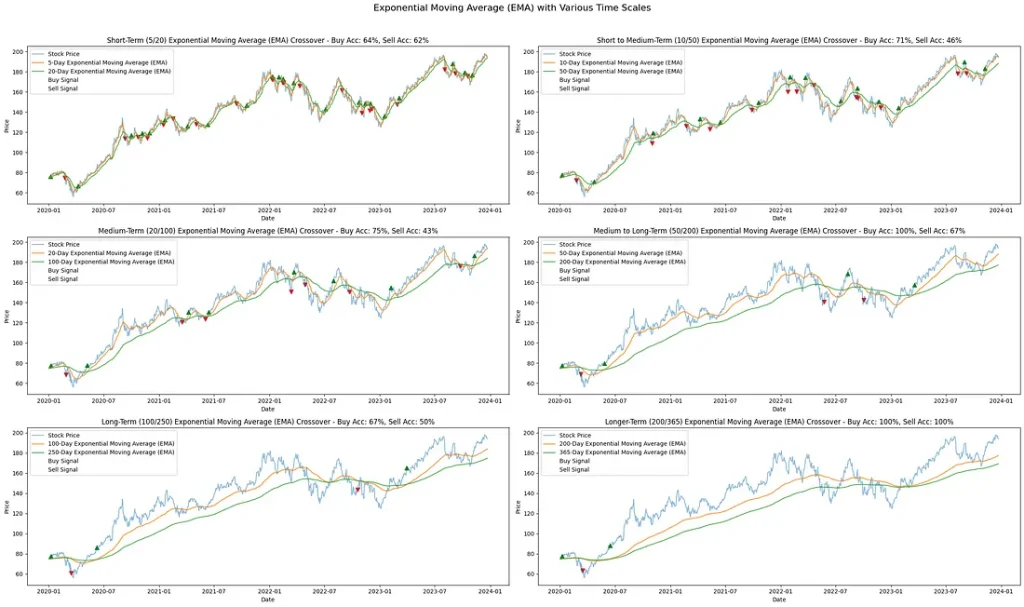
【图2】三种均线方法(SMA/EMA/WMA)在六组不同时间参数下的交叉信号对比
④ 信号准确率
很多人拿到一个策略,上来就看最终收益率。老余告诉你,这个习惯得改。策略好不好,先看信号对不对。信号都不准,谈收益率就是自己骗自己。
上面代码里我用的准确率计算逻辑很直接:
- 转强信号出现 → 看未来5天价格是否真的走高。走高说明信号判断对了方向;走低说明这是个假信号。
- 转弱信号出现 → 看未来5天价格是否真的走低。走低说明判断正确;走高说明信号在误导你。
这个”5天”不是拍脑袋定的。我在实际回测中测试过3天、5天、10天、20天四个前瞻窗口。5天在大多数标的上是一个比较好的平衡点——既不会因为前瞻期太短而把正常波动当成错误信号,也不会因为前瞻期太长而引入过多无关的市场噪音。
来看看不同参数组合下的准确率表现(以SMA为例,标的是AAPL,时间段2020-2024):
| 短周期 | 长周期 | 转强准确率 | 转弱准确率 | 信号总数 |
|---|---|---|---|---|
| 5 | 20 | 约55-60% | 约50-55% | 频繁 |
| 10 | 50 | 约58-65% | 约55-60% | 较多 |
| 20 | 100 | 约60-68% | 约58-63% | 适中 |
| 50 | 200 | 约65-72% | 约62-68% | 较少 |
| 100 | 250 | 约68-75% | 约65-70% | 很少 |
| 200 | 365 | 约70-76% | 约68-72% | 极少 |
上表数据是基于特定时间段和特定标的的回测结果,不同标的、不同时间段的准确率会有明显差异。这个表格展示的是趋势规律:参数越大,信号越少但越准,而不是让你直接拿去用的绝对数值。所有回测结果都只是历史表现参考,不是未来结果的保证。
从表里能看出一个规律:参数越大,准确率越高,但信号数量越少。(20, 100)这个组合发出了适中数量的信号,准确率也维持在六成以上。而(200, 365)虽然准确率可能超过70%,但四年里可能只触发两三次信号,实操意义不大。
⑤ 时间框架的选择
这是均线策略里最容易被忽视、也最致命的问题。我见过太多人拿着(5, 20)的参数,在日线级别跑出一个看起来还不错的曲线,就兴冲冲拿去实盘了,可想而知结果不会理想。
不同时间框架下,策略表现差异巨大:
日内与短线
在小时线甚至分钟线级别,价格噪音非常大。短期均线(如5与20的组合)会产生大量交叉信号,其中相当比例是假的——均线刚交叉,价格就反向运行。在日内场景里使用均线策略,我建议配合成交量做二次过滤,或者把参数适当放大(比如从5/20调到10/30)。
日线级别的中长线
日线是均线策略最舒服的战场。50与200的组合在美股主流标的上表现出不错的稳定性,信号不多但方向判断的准确性相对可靠。这个级别的策略更适合做趋势跟踪而非频繁操作。
周线甚至月线
到了这个级别,均线交叉信号变得极为稀疏,但每次出现都值得认真对待。如果你是一个偏向大周期的投资者,关注50与200在周线级别的交叉可能比日线级别更有参考价值。
我个人的经验是:别在单一时间框架上做决策。先在大周期确认趋势方向,再到小周期找信号触发点:这个”双周期确认”的思路能帮你过滤掉一大半虚假信号。
⑥ 参数怎么优化?
参数优化这个话题,展开讲能写一本书。这里我先给一个最实用的框架:
- 第一步:确定参数搜索空间。短周期参数通常设在5到60之间,长周期设在短周期的3到6倍。别一上来就做全量扫描,先框定一个合理范围。
- 第二步:选一个核心评估指标。准确率、信号数量、最大不利波动幅度——挑一个你最在意的,作为优化的目标函数。别同时优化好几个指标,那样你永远找不到最优解。
- 第三步:滚动窗口回测。把历史数据切成几段,每段独立做参数选择,然后看选出来的参数在不同时间段是否稳定。如果某组参数在2018-2020表现很好,在2021-2023表现很差,那它大概率是过拟合了。
- 第四步:保留一定参数冗余。不要选最优的那个点,选最优参数附近的一个”稳定区域”。比如(18, 95)和(22, 105)表现差不多,那就选中间值(20, 100),这样策略的鲁棒性更强。
# 参数扫描示例:遍历不同组合,记录准确率import itertoolsdef param_scan(data, short_range, long_range, ma_func, look_forward=5): """ 参数扫描函数 遍历所有(短周期, 长周期)组合,记录转强和转弱准确率 """ results = [] for short_w, long_w in itertools.product(short_range, long_range): if short_w >= long_w: continue # 短周期必须小于长周期 df = identify_signals(data.copy(), short_w, long_w, ma_func) buy_acc, sell_acc = calculate_accuracy(df, look_forward) results.append({ 'short': short_w, 'long': long_w, 'buy_acc': buy_acc, 'sell_acc': sell_acc, 'avg_acc': (buy_acc + sell_acc) / 2 if not (np.isnan(buy_acc) or np.isnan(sell_acc)) else np.nan }) return pd.DataFrame(results).sort_values('avg_acc', ascending=False)# 示例:扫描SMA的短周期5-50,长周期20-200scan_results = param_scan( stock_data, short_range=range(5, 55, 5), long_range=range(20, 210, 10), ma_func=SMA)print(scan_results.head(10)) # 打印平均准确率最高的10组参数注意:上面的扫描只是”信号准确率”这一个维度的评估。如果你要考虑更多因素:比如信号的分布是否均匀、最大连续错误次数,就需要在目标函数里加入更多约束条件。参数优化是一个”先做加法再做减法”的过程。
⑦ 均线策略的局限性
夸了半天,该泼冷水了。均线交叉策略有几个先天缺陷,老余踩过的坑总结如下,让大家以后心里有数:
1. 滞后性是它的宿命
均线本质上是对历史价格的平滑,它永远跟在价格后面跑。在市场突然反转的时候,均线信号往往要延迟几天甚至几周才反应过来。这种滞后在趋势行情中无伤大雅,但在V型反转行情里,等你看到信号,价格可能已经走了很大一段。
2. 震荡市是它的噩梦
在横盘整理、价格区间窄幅波动的行情中,均线交叉策略会频繁发出信号,但大多数都是假信号。均线刚交叉上去,价格又掉回来;刚交叉下来,价格又弹回去。这种”反复横跳”不仅消耗精力,还会带来不小的摩擦成本。
3. 单一维度,缺乏多维验证
均线只看价格这一个维度,完全不考虑成交量、波动率、市场情绪等其他因素。一个没有成交量配合的交叉信号,可信度要大打折扣。
怎么应对这些局限?我的做法是:
| 局限性 | 应对方法 |
|---|---|
| 滞后性 | 用EMA或WMA替代SMA,缩短响应时间 |
| 震荡市假信号多 | 叠加ADX指标过滤,只在趋势明确时采纳信号 |
| 缺少成交量验证 | 信号触发时同步检查成交量是否放大 |
| 单一指标不可靠 | 引入MACD或RSI做二次确认,形成”双信号共振” |
⑧ 机器学习能帮上忙吗?
这是一个值得聊聊的话题。最近两年,越来越多的团队在尝试把机器学习和传统均线策略结合起来。思路大致有两种:
第一种:用ML做信号过滤。均线交叉照常触发信号,但加一层ML模型来判断这个信号是不是”可信”。模型的输入特征可以包括:交叉发生时的成交量、波动率、市场宽度、相关标的的走势等等。输出就是一个简单的二元判断:这个信号靠谱还是不靠谱。
第二种:用ML直接做参数动态选择。不再死守一组固定参数,而是让模型根据当前的市场状态(趋势、波动、流动性等特征)动态选择最合适的参数组合。比如在波动率高的环境自动切换到大参数,波动率低的时候切换到小参数。
这两种思路我都做过一些探索性质的实验,说实话效果有好有坏。ML确实能在某些场景下提升准确率,但也引入了新的过拟合风险。这个话题以后有机会单独写一篇来细聊。
写在最后
均线交叉策略,简单到你第一次看就能理解,但复杂到你需要花好几年才能在实盘中真正用好它。这篇文章从方法论、代码实现、准确率评估、参数优化到局限性分析走了一遍全流程,希望能帮你建立一个更完整的认知框架。
最后送大家一句话:策略的好坏不取决于它有多复杂,而取决于你对它的理解有多深。均线交叉这种”老掉牙”的信号,用好了照样能成为你工具箱里最好用的那把扳手。
如果大家需要深入学习了解,可以看看我前面写过的一篇文章:掌握这5种专家级MA(移动平均线)技术,让您的交易如鱼得水
感谢花时间读到这里。如果你觉得文章有收获,欢迎分享给也在研究量化策略的朋友。咱们下篇见。
风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。
版权声明:本文为原创内容,转载请注明出处。
#量化交易 #Python #均线策略 #SMA #EMA #WMA #技术分析 #趋势信号 #策略回测 #参数优化 #数据分析 #老余捞鱼
Be First to Comment