作 者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:如果你还在用均线和MACD做决策,那这篇文章会打开一扇新大门。今天,我把机器学习在量化金融中的应用,从最基础的线性回归一路讲到最前沿的深度强化学习,全部掰开揉碎了讲给你听。不整虚的,全是干货。
最近跟几个做量化的朋友聊天,发现一个有意思的现象:以前大家聊的是均线金叉、布林带突破,现在开口闭口都是XGBoost、Transformer、注意力机制。
这不是装逼,而是整个行业真的在发生一场静悄悄的革命。
过去十年,华尔街和对冲基金已经把机器学习从实验室搬到了交易台前。根据麦肯锡2024年的报告,全球头部对冲基金中超过70%已经在生产环境中部署了某种形式的AI/ML系统。而国内的量化圈,也在最近两三年迎来了爆发式增长。
但问题是:这些算法到底是怎么工作的?它们凭什么能比传统方法更有效?又有哪些坑是新手一定会踩的?
今天这篇长文,我就按照由浅入深的顺序,把机器学习在金融领域的完整知识体系梳理一遍。不管你是刚入门的小白,还是有一定基础的从业者,也许都能从中找到有价值的内容。
泡好咖啡,我们开始。
第一步:监督学习打地基,一切从这里开始
在金融领域,我们手里最多的东西是什么?历史数据。股价走势、财务报表、宏观经济指标……这些数据都有一个共同特点:我们知道过去发生了什么。
当我们用这些”有答案”的数据去训练模型时,这就叫监督学习(Supervised Learning)。它是所有机器学习方法中最基础、也是最成熟的一类。
1. 线性回归与过拟合陷阱
任何机器学习的旅程,几乎都从线性回归(Linear Regression)开始。
举个具体的例子:假设你想做一个时间序列动量策略,想用过去5天的收益率来预测明天的收益率。线性回归做的事情很简单,它试图在这些数据点之间画一条直线,找到输入和输出之间的关系。
听起来很美好,但这里有一个巨大的坑:过拟合(Overfitting)。
⚠️ 老余提醒:过拟合是量化新手最大的敌人!
金融数据的噪声极大。如果你的模型太简单,它会漏掉真正的规律(欠拟合);如果你让模型变得极其复杂(比如用高阶多项式),它会记住每一个数据点的随机波动,而不是学到真正的模式。结果就是:回测看起来像天才,实盘一上就亏钱。
我见过太多这样的案例:回测年化收益80%,夏普比率3.5,一到实盘就连续亏损。原因往往不是策略逻辑有问题,而是过拟合在作祟。
2. 正则化:给模型踩刹车
怎么解决过拟合?量化圈的标准答案是:正则化(Regularization)。
你可以把它理解为给学习过程装了一个”刹车装置”。常用的正则化方法有三种:
| 方法名称 | 核心思想 | 适用场景 |
|---|---|---|
| Ridge(L2正则化) | 惩罚系数的平方和,让所有系数都变小但不归零 | 特征之间存在多重共线性时 |
| Lasso(L1正则化) | 惩罚系数的绝对值之和,能把不重要特征的系数压缩到零 | 需要做特征选择时 |
| ElasticNet | 结合L1和L2的优点,同时实现收缩和选择 | 特征多且相关性高时 |
💡 一句话理解:Ridge像是一个温和的老师,让每个学生都少写一点作业;Lasso则像一个严格的老师,直接告诉某些学生”你不用写了”。ElasticNet则是两者的平衡。
第二步:分类问题,方向比幅度更重要
在实际交易中,预测一只股票具体涨多少是非常困难的。很多时候,我们只需要回答一个更简单的问题:明天是涨还是跌?
这就是从回归问题转向分类问题(Classification)的核心动机。
1. 逻辑回归与朴素贝叶斯
逻辑回归(Logistic Regression)虽然名字里带着”回归”,但它实际上是一个分类算法。它通过一个S形曲线(sigmoid函数),把输出映射到0到1之间的概率值。比如:”市场明天上涨的概率是65%”。
朴素贝叶斯(Naive Bayes)则是另一种思路,它基于贝叶斯定理,随着新证据的不断出现来更新我们的信念。比如当一份超预期的财报发布后,系统会自动调整对这只股票上涨概率的判断。
📊 重要提醒:不要迷信准确率!
如果市场天然有55%的时间在上涨,一个永远猜”涨”的傻瓜模型也能拿到55%的准确率,但它没有任何实际价值。
业内真正使用的评估指标是 ROC曲线 和 AUC值(曲线下面积),它们衡量的是模型区分”赢家”和”输家”的真实能力。
2. 支持向量机(SVM):画一条最宽的分界线
当”涨”和”跌”的分界线不是一条直线时怎么办?这时候就轮到支持向量机(Support Vector Machine, SVM)登场了。
SVM的核心思想很优雅:它试图找到一个超平面(hyperplane),使得不同类别之间的间隔(margin)尽可能大。而且通过核技巧(kernel trick),它还能处理非线性可分的情况。
不过说实话,在当今的量化实践中,SVM的使用频率已经不如从前了。原因很简单,后面要讲的树模型和集成方法,在大多数场景下效果更好。
第三步:无监督学习,让数据自己说话
前面说的都是有标签的学习,我们知道每条数据对应的答案是什么。但如果没有标签呢?
假设你手上有几千只股票,想要找出隐藏的模式和结构。这时候就需要无监督学习(Unsupervised Learning)了。
1. 聚类分析:构建真正分散的组合
传统的行业分类(科技、能源、医疗)看似合理,但有时候数据会告诉我们不同的故事。
使用K-Means聚类或层次聚类(Hierarchical Clustering),我们可以完全基于统计行为来分组资产,考虑风险、收益率、波动率、Beta等指标。模型可能会揭示出:某只科技股的行为模式更像公用事业股。✅ 实战价值:这种基于统计行为的聚类,能帮助你构建数学意义上真正分散的投资组合,而不是仅仅依赖传统行业分类的表面分散。
2. 主成分分析(PCA)与收益率曲线
金融数据集经常面临一个叫“维度诅咒”(Curse of Dimensionality)的问题,变量太多且高度相关。
以美国国债收益率曲线为例:1个月、3个月、1年、5年、10年、30年期国债收益率……这些变量之间高度相关。把它们全部放进模型,不仅计算量大,还会引入噪声。
主成分分析(Principal Component Analysis, PCA)的作用就是把这些高度相关的变量压缩成少数几个独立的”主成分”。
💡 有趣的发现:
当你对美国国债收益率曲线做PCA时,数学自然而然地重新发现了债券市场的三个基本力量:
• 水平因子(Level):整体利率水平的平行移动
• 斜率因子(Slope):长短端利差的变化(扭曲)
• 曲率因子(Curvature):中期相对于两端的变化(蝴蝶形态)
这绝不是巧合,而是说明PCA确实捕捉到了驱动市场的底层经济因素。
第四步:集成学习,三个臭皮匠顶个诸葛亮
单个决策树(Decision Tree)的好处是可解释性强,它就像一系列”是/否”问题的组合(比如”市盈率大于15吗?”),最终得出结论。
但单棵树的问题也很明显:容易过拟合。
解决方案?集成方法(Ensemble Methods)把多个模型组合起来,形成一个”超级模型”。
| 集成方法 | 核心思想 | 代表算法 | 优势 |
|---|---|---|---|
| Bagging(装袋法) | 并行训练多个独立模型,取投票结果 | Random Forest(随机森林) | 大幅降低方差 |
| Stacking(堆叠法) | 训练不同类型的基模型,再用元模型融合 | 多模型堆叠 | 适应不同市场环境 |
| Boosting(提升法) | 串行训练,每棵新树专门修正前一棵的错误 | XGBoost / LightGBM / CatBoost | 表格数据领域当前最强 |
XGBoost:表格数据的王者
说到Boosting,就不得不提XGBoost。它是目前结构化数据(表格数据)领域无可争议的王者。
它的原理可以这样理解:
- 第一轮:训练一棵简单的决策树。
- 第二轮:看看第一棵树哪里猜错了(残差),再训练一棵树专门修正这些错误。
- 第三轮:继续修正前两棵树的剩余错误。
- ……如此迭代,直到达到预设的轮数或误差足够小。
🏆 为什么XGBoost在金融界这么火?
根据Kaggle竞赛和工业界的经验,XGBoost在以下金融任务中表现卓越:
• 信用风险评估(违约概率预测)
• 欺诈检测(信用卡反欺诈)
• 市场方向预测(涨/跌分类)
• 定价模型(保险、衍生品定价)
在2024年的各大金融AI竞赛中,XGBoost及其变体仍然占据着榜单前列的位置。
下面是一段XGBoost用于信用风险建模的简化代码示例:
# XGBoost 信用风险建模示例import xgboost as xgbfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_score# 假设已加载并预处理好的数据# X: 特征矩阵 (年龄, 收入, 负债比例, 历史还款记录...)# y: 标签 (0=正常还款, 1=违约)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建XGBoost分类器model = xgb.XGBClassifier( objective='binary:logistic', # 二分类任务 eval_metric='auc', # 用AUC作为评估指标 max_depth=6, # 树的最大深度 learning_rate=0.05, # 学习率 n_estimators=300, # 迭代轮数 scale_pos_weight=10 # 处理类别不平衡)# 训练模型(带早停机制防止过拟合)model.fit( X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=20, verbose=False)# 预测并评估y_pred_proba = model.predict_proba(X_test)[:, 1]print(f"测试集AUC: {roc_auc_score(y_test, y_pred_proba):.4f}")第五步:深度学习,进入深水区
当传统机器学习方法遇到瓶颈时,就该深度学习(Deep Learning)出场了。
人工神经网络(Artificial Neural Networks, ANNs)的灵感来源于人脑的结构。数据通过多层”神经元”传递,每一层都会应用非线性的激活函数(如ReLU),从而捕捉极其复杂的市场动态。
深度学习的真正魔法:优化
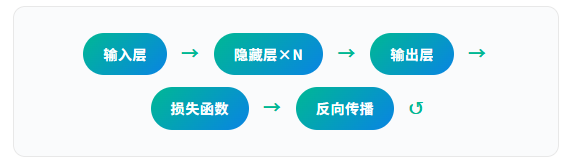
神经网络的工作流程可以概括为三步循环:
- 前向传播:数据从输入层经过各层处理,得到预测结果。
- 损失计算:对比预测值和真实值,计算误差(Loss Function)。
- 反向传播:利用微积分(梯度下降)更新每个神经元的权重参数。
现代优化器如Adam,就像一个聪明的登山者——它在迷雾笼罩的山坡上行走,能动态调整步伐大小,努力找到全局最低点(全局最小值),而不是卡在某个局部坑洼里(局部最小值)。
第六步:前沿应用,现代对冲基金的武器
掌握了基础算法之后,我们来看看顶级机构正在用的那些更高级的技术。
1. 自然语言处理(NLP):读懂文字里的信号
数字只能告诉你一半的故事。另一半藏在文字里。
量化团队现在大量使用NLP模型(如Transformer架构、FinBERT)来实时”阅读”以下内容:
- SEC监管文件(年报、季报、公告);
- 财报电话会议的文字记录;
- 实时新闻推送和社交媒体情绪;
- 央行官员的讲话稿;
通过提取情绪分数(Sentiment Score)比如衡量CEO发言中乐观词汇与悲观词汇的比例,系统能够在人类分析师读完标题之前就完成信息消化和决策。
✅ 实际案例:2024年的一项研究显示,基于FinBERT的美联储议息会议纪要情绪分析,能够提前预测约60%的货币政策走向变化,为固定收益交易提供了显著的alpha来源。
2. 强化学习(RL):从试错中学会最优策略
前面的方法都是在”预测下一个价格”。而强化学习(Reinforcement Learning)走了一条完全不同的路,它不预测价格,而是学习如何做决策。
你可以把RL交易智能体想象成一个电子游戏角色:
- 环境:股票市场;
- 动作:持有 / 操作(根据策略规则执行);
- 奖励:盈利(正奖励)或亏损(负奖励)。
经过数百万次的模拟训练,Q-Learning等算法能让智能体逐步学会在不同市场状态下采取最优的行动序列,以最大化长期财富积累。⚠️ 注意:强化学习在金融中的应用仍处于探索阶段。模拟环境和真实市场之间存在巨大差距(所谓的”模拟-现实鸿沟”),直接将RL策略部署到实盘需要极其谨慎的验证过程。
3. 可解释性AI(XAI):打开黑盒子
深度学习模型的一个致命弱点是:黑箱特性。当一个ML系统拒绝了一笔贷款申请时,监管机构和客户都有权知道为什么。
SHAP(SHapley Additive exPlanations)是目前业界最流行的解释工具之一。它能逆向分解模型的决策过程,精确地告诉你是哪些特征导致了某个特定的预测结果。
💡 SHAP的实际价值:
假设银行拒绝了一个贷款申请,SHAP可以让银行明确地说:”您的申请被拒绝,是因为近期的征信查询次数过多这一负面因素,超过了您稳定收入带来的正面影响。”这种透明度对于合规和客户信任至关重要。
SHAP解释XGBoost模型的代码示例:
import shapimport xgboost# 训练好的XGBoost模型model = xgboost.train(params, dtrain)# 创建SHAP解释器explainer = shap.TreeExplainer(model)# 计算SHAP值(解释单个预测)shap_values = explainer.shap_values(X_test)# 可视化单个样本的特征贡献shap.force_plot(explainer.expected_value, shap_values[0], X_test.iloc[0], matplotlib=True)第七步:实战中的拦路虎
了解了算法原理只是第一步。要把这些方法真正用到 messy 的真实世界中,你还需要跨过好几道坎。
1. 数据不平衡问题(SMOTE)
在信用风险建模中,99%的人按时还贷,只有1%的人违约。如果模型每次都猜”不会违约”,它也能声称99%的准确率,但这毫无意义。
业界的标准做法之一是使用SMOTE(Synthetic Minority Over-sampling Technique)在训练过程中合成一些合理的”假”违约样本,强制算法去学习违约案例的特征模式。
2. 超参数调优:寻找最佳配置
每个ML模型都有一堆叫做超参数(Hyperparameters)的设置项——比如树的深度、神经网络的学习率、正则化的强度等等。
| 调优方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 网格搜索 | 穷举所有参数组合 | 保证找到最优 | 极慢,维度灾难 |
| 随机搜索 | 随机采样参数空间 | 比网格搜索快 | 依赖运气 |
| 贝叶斯优化 | 利用历史结果指导下一步搜索 | 高效,智能 | 实现较复杂 |
| 模拟退火 | 模仿金属退火过程的启发式搜索 | 避免局部最优 | 需调节温度参数 |
🔧 老余的经验之谈:
贝叶斯优化和模拟退火就像是玩”战舰棋”的高手:它们会利用之前的”命中”和”未命中”记录,聪明地推测最佳参数藏在哪里。这比盲目搜索效率高出数倍,对于需要频繁优化的实盘策略来说尤其重要。
3. 避免前视偏差(Look-ahead Bias)
这是量化研究中最容易犯也最致命的错误之一。
简单来说,就是在训练模型时不小心使用了”未来才应该知道”的信息。比如用当天收盘价来预测当天盘中走势,或者在计算技术指标时使用了包含当期在内的未来数据。
⚠️ 血泪教训:
我见过无数回测完美的策略,仔细审查后发现都存在不同程度的前视偏差。一旦消除这个偏差,很多”圣杯级”策略瞬间变成了平庸甚至亏损的策略。
防范原则:严格按时间顺序切分训练集和测试集,确保模型在任何时刻只能使用该时刻之前的信息。
写在最后
看到这里,你应该已经对机器学习在量化金融中的应用有了比较完整的认识。
我想强调的是:ML在金融中的应用,远不是”往墙上扔数学公式看哪个能粘住”那么简单。 它是一条严谨的、环环相扣的流水线,你需要精心设计特征工程,选择能在偏差和方差之间取得平衡的模型,克服数据不平衡问题,进行智能的超参数优化,并且在整个过程中严防前视偏差等各种陷阱。
无论你是在用XGBoost预测信用违约,还是用NLP解析美联储主席的讲话,亦或是用深度学习建模收益率曲线,你都正在参与人类历史上最精密的量化金融时代。
当然,工具本身不是目的。再先进的算法,也需要正确的投资理念、严谨的风控体系和持续迭代的执行力来配合。技术是杠杆,但支点始终是你对市场的理解。
本文要点回顾
- 监督学习(线性回归、逻辑回归、SVM)是量化ML的基础,但必须警惕过拟合陷阱。
- 正则化(Ridge/Lasso/ElasticNet)是控制过拟合的核心手段,相当于给模型装刹车。
- 无监督学习(聚类、PCA)帮助我们发现数据中的隐藏结构和降低维度。
- 集成方法中,XGBoost/LightGBM是当前表格数据领域的首选算法,尤其在风控和欺诈检测中表现突出。
- 深度学习、NLP(FinBERT)、强化学习和可解释性AI(SHAP)代表了当前的前沿方向。
风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。
版权声明:本文为原创内容,转载请注明出处。
#机器学习 #量化金融 #深度学习 #XGBoost #NLP #强化学习 #风险管理 #特征工程 #PCA #金融科技 #模型调优 #可解释AI
Be First to Comment