作者:老余捞鱼
原创不易,转载请标明出处及原作者。
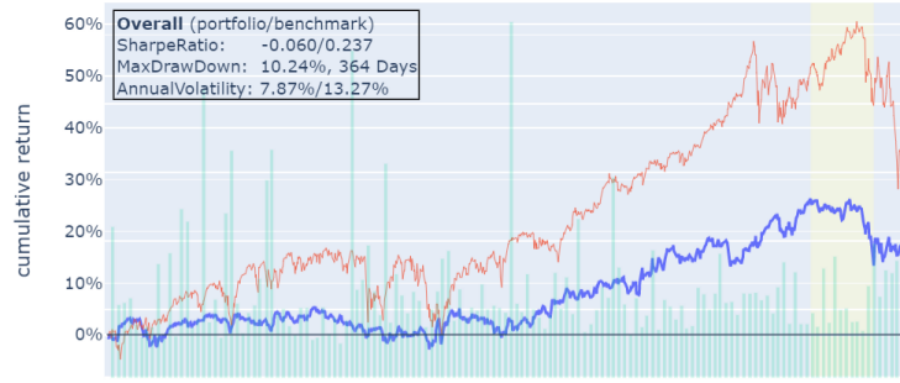
写在前面的话:今天给大家安利一个GPU加速的量化开源库:Spectre。它基于PyTorch,能在RTX 3090上把因子分析和回测速度提升77倍。从安装到实战,我全给你捋清楚了。
做量化的人都知道一个痛点:跑一次回测,喝杯咖啡回来还没跑完。尤其是因子分析这种需要遍历几千只标的、几十个因子的活儿,CPU算起来那是真的慢。今天给大家聊一个让我眼前一亮的开源库:Spectre,它基于PyTorch,能把GPU的算力直接灌进因子分析和策略回测里,RTX 3090上最高提速77倍。来,我全给你捋清楚。
一、量化研究的两大核心:因子分析 & 回测
先说基础。量化投资的核心流程,说白了就两件事:
因子分析,就是从海量数据里找到那些能解释资产表现差异的变量。比如动量、波动率、价值指标,这些都是经典因子。因子的质量直接决定了策略的上限。
回测,就是拿历史数据模拟你的策略表现,看看这套逻辑在过去到底行不行。它是验证策略可行性的关键步骤,也是优化参数的主要手段。
问题在于,这两件事都非常吃算力。数据集动辄覆盖几千只标的、几十年的时间跨度,数据量轻松上GB。用传统的CPU工具跑,一个复杂因子组合可能要等几十分钟甚至几个小时。在高频研究和迭代场景下,这种等待就是在浪费机会。
量化圈的铁律:研究速度 = 策略迭代速度 = 竞争力。别人一天能测100个因子,你只能测10个,差距就是这么拉开的。
目前主流的Python量化库,像Zipline、Backtrader,基本都是CPU运算,面对大规模数据集时性能瓶颈明显。Spectre正是瞄准了这个痛点来的,用GPU并行计算,把速度拉满。
二、Spectre是什么?
Spectre是一个开源的Python量化交易库,专攻两个方向:高性能因子分析和策略回测。它基于PyTorch构建,核心卖点是GPU加速:调用一个to_cuda()方法,就能把计算任务扔到NVIDIA显卡上,利用数千个CUDA核心并行处理,速度直接起飞。

和Pandas、NumPy这种通用数据分析库不同,Spectre是专门为量化研究量身打造的。它能高效处理OHLCV(开盘价、最高价、最低价、收盘价、成交量)数据,支持自定义因子创建,还能和Pyfolio、Alphalens这些专业分析工具无缝对接。

三、底层原理:DAG引擎 + CUDA并行
速度不是凭空来的,Spectre的底层设计有两个关键点。
1. DAG有向无环图:因子计算的正确打开方式
Spectre把每个因子(比如SMA、RSI)设计成DAG图中的一个节点。节点之间的依赖关系决定了计算顺序:先算哪个、后算哪个,一目了然。这种设计有一个非常重要的好处:杜绝前视偏差。
前视偏差是量化研究中的大忌,就是”用未来的数据算过去的结果”。DAG通过严格的依赖排序,确保每个因子只能访问它依赖的上游数据,不会出现信息泄露。这对保证回测结果的可靠性至关重要。
为什么DAG这么重要?
举个简单的例子:你要算"20日动量因子",它依赖"收盘价"和"收益率"。DAG会先算收益率,再算动量,顺序不会搞反。如果因子之间有循环依赖,DAG会直接报错,而不是默默给出一个有偏差的结果。
2. CUDA并行计算:把显卡算力吃满
调用to_cuda()后,Spectre把所有张量运算转移到GPU上执行。RTX 3090有10496个CUDA核心,这意味着同一时刻可以并行计算上千个标的的因子值。对于EMA、RSI这类需要在时间序列上滚动计算的因子,GPU的加速效果尤为明显。
根据官方基准测试数据,在RTX 3090上计算复杂因子组合,相比纯CPU运算,加速比最高可达77倍。这是什么概念?原来需要一个小时跑完的因子分析,现在不到一分钟就能出结果。
| 计算场景 | CPU耗时 | GPU耗时 (RTX 3090) | 加速倍数 |
|---|---|---|---|
| 简单因子 (SMA/RSI) | ~5分钟 | ~10秒 | ~30x |
| 中等复杂因子组合 | ~30分钟 | ~30秒 | ~60x |
| 复杂因子+自定义因子 | ~60分钟 | ~47秒 | ~77x |
注:以上数据为官方文档公布的基准测试结果,实际表现因数据规模和硬件配置不同会有差异。
四、数据加载与回测引擎
数据加载
Spectre内置了多种数据加载器,支持CSV、Arrow(Feather格式)等常见数据格式,还提供了YahooDownloader可以直接从雅虎财经下载数据。数据加载后,会被整理成多层索引的Pandas DataFrame:日期为行索引,标的代码为列索引,这也是量化分析师最熟悉的数据格式。
回测引擎
Spectre的回测模块采用事件驱动架构,按时间顺序逐条处理行情数据。它内置了订单管理系统(Blotter),支持手续费、滑点、止损等真实交易成本的模拟,让回测结果更贴近实盘表现。
回测输出可以直接对接Pyfolio生成完整的绩效报告——夏普比率、最大回撤、年化收益等核心指标一应俱全,也可以用Alphalens生成因子分位数收益图和IC分析图。
实用建议
回测时一定要加上手续费和滑点,否则结果会严重失真。Spectre的Blotter系统默认就支持这些参数,别偷懒跳过。
五、手把手安装教程
安装Spectre不算复杂,但有几个依赖项需要注意,尤其是GPU支持部分。老余一步一步带你走。
前置条件
- Python 3.7+(建议3.9以上,稳定性更好)
- PyTorch 1.3+(需要CUDA版本才能用GPU加速)
- Pandas 1.0+
- NVIDIA GPU(建议RTX系列,3090/4090效果最佳)
第一步:安装PyTorch(CUDA版)
去PyTorch官网,根据你的系统、CUDA版本选择对应的安装命令。以CUDA 11.8为例:
# 安装PyTorch CUDA版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118第二步:安装依赖库
Spectre不自带这些依赖,需要手动安装:
pip install pyarrow pandas tqdm plotly requests beautifulsoup4 lxml第三步:安装Spectre
从GitHub安装,用--no-deps跳过自动依赖,避免版本冲突:
pip install --no-deps git+https://github.com/Heerozh/spectre.git第四步:验证安装
import spectre
print(spectre.__version__) # 应输出类似 '0.3.1'
# 检查CUDA是否可用
import torch
print(torch.cuda.is_available()) # True表示GPU可用第五步:准备数据
可以用yfinance下载历史数据,并转存为Arrow格式(加载更快):
import yfinance as yf
import pyarrow as pa
import pyarrow.feather as feather
import pandas as pd
# 定义标的池
tickers = ['AAPL', 'MSFT', 'GOOGL']
# 下载数据
data = yf.download(tickers, start='2010-01-01', end='2023-12-31')
data = data.stack(level=1).reset_index().rename(columns={'level_1': 'symbol'})
data.columns = [col.lower() for col in data.columns]
# 存为Arrow格式
table =pa.Table.from_pandas(data)
feather.write_feather(table, 'yahoo_data.feather')常见坑
1. GPU驱动必须更新到最新版本,否则可能CUDA不可用;2. 大数据集建议分块加载,避免显存溢出;3. 如果没有NVIDIA显卡,Spectre会自动降级为CPU模式,但速度优势就没了。
六、实战演练:从因子计算到完整回测
安装好了,我们来跑几个实际例子。从简单到复杂,一步步来。
场景1:基础因子计算
加载历史数据,计算50日均线和14日RSI:
from spectre import factors
from spectre.data import ArrowLoader
# 加载数据
loader = ArrowLoader('yahoo_data.feather')
engine = factors.FactorEngine(loader)
# 切换到GPU模式
engine.to_cuda()
# 添加内置因子
engine.add(factors.SMA(50), 'sma50') # 50日均线engine.add(factors.RSI(14), 'rsi14') # 14日RSI
# 运行因子计算
df = engine.run('2020-01-01', '2023-12-31')
print(df.head())输出的DataFrame包含每个标的在每个日期的因子值。在实际使用中,你可以用RSI筛选超买区域,用均线判断趋势方向,这些都是常见的因子应用方式。
场景2:自定义因子
内置因子不够用?你可以自己造。下面是一个”动量-波动率复合因子”的例子——衡量的是风险调整后的动量表现:
from spectre.factors import Factor, LogReturns, EMA
class MomentumVol(Factor):
inputs = [LogReturns(1)]
window = 20
def compute(self, close):
ret = self.inputs[0]
mom = EMA(ret, 20) # 收益率的指数移动平均
vol = mom.rolling_std(20) # 波动率
return mom / vol # 风险调整后的动量
engine.add(MomentumVol(), 'mom_vol')
df = engine.run('2020-01-01', '2023-12-31')这个因子的含义很直观:动量高但波动率低的标的得分更高,适合用来筛选风险收益比较好的品种。在组合构建中,这种因子可以作为权重分配的参考依据。
场景3:完整回测流程
因子算完了,来跑一个完整的策略回测——动量轮动策略,每月底调仓:
from spectre.trading import CustomAlgorithm, Backtest
from spectre.portfolio import Blotter
classMomentumStrategy(CustomAlgorithm):
definitialize(self):
self.add(factors.Momentum(252), 'mom')
self.schedule_rebalance('month_end')
defrebalance(self):
mom = self.get_values('mom')
longs = mom[mom > 0].index
self.portfolio.set_target_percent(
{sym: 1/len(longs) for sym in longs}
)
defterminate(self):
self.portfolio.plot_returns()
# 运行回测
loader = ArrowLoader('yahoo_data.feather')
algo = MomentumStrategy(loader)
backtest = Backtest(algo)
results = backtest.run('2014-01-01', '2018-12-31')
print(results.summary())加上手续费和滑点也很简单:
blotter = Blotter(commission=0.001, slippage=0.0005)
algo.blotter = blotter回测结果会输出夏普比率、年化收益、最大回撤等核心绩效指标。如果需要更深入的因子分析,可以对接Alphalens:
import alphalens as al
factor_data = engine.run(
'2014-01-01', '2018-12-31',
forward_returns_periods=[1, 5, 21]
)
al.tears.create_full_tear_sheet(factor_data)这会生成完整的因子分析报告,包括分位数收益图、IC值走势等,是专业投研报告的标准配置。
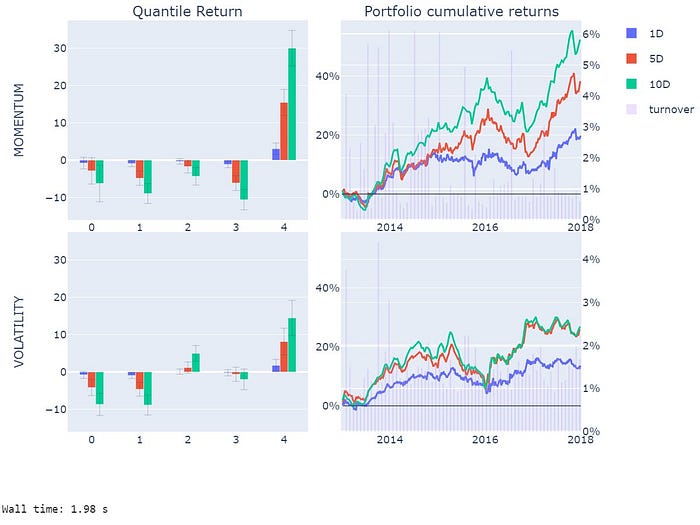
七、进阶玩法:与深度学习模型集成
Spectre基于PyTorch,这意味着你可以直接把神经网络模型嵌入因子计算流程。比如用全连接网络预测收益:
import torch.nn as nn
class NeuralFactor(Factor):
def compute(self, inputs):
model = nn.Sequential(
nn.Linear(10, 5),
nn.ReLU(),
nn.Linear(5, 1)
)
return model(inputs) # 简化示例,实际需单独训练
engine.add(NeuralFactor(inputs=[factors.SMA(10), factors.RSI(14)]), 'neural_pred')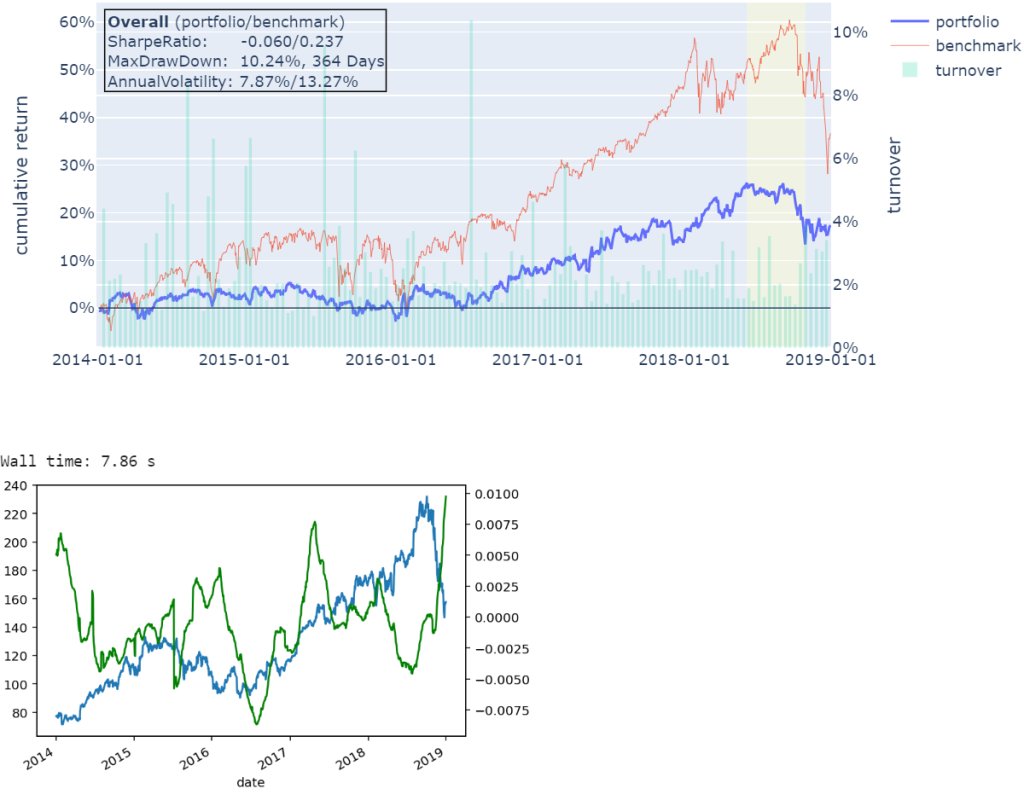
这打开了AI驱动因子的想象空间:用神经网络预测收益、用强化学习优化调仓逻辑,这些都是传统因子库做不到的事情。对于有ML背景的量化团队来说,Spectre的PyTorch基因是一个巨大的加分项。
八、Spectre vs 主流量化库对比
光说不练假把式,我把Spectre和几个主流Python量化库放在一起对比一下:
| 特性 | Spectre | Zipline | Backtrader |
|---|---|---|---|
| 计算架构 | GPU (CUDA) | CPU | CPU |
| 加速比 (vs CPU) | 最高77x | 1x | 1x |
| 因子引擎 | DAG有向无环图 | 无独立因子引擎 | 指标库 |
| 自定义因子 | 支持 | 有限支持 | 支持 |
| ML集成 | 原生PyTorch | 需外部集成 | 需外部集成 |
| 前视偏差防护 | DAG自动防护 | 部分支持 | 需手动处理 |
| 数据格式 | CSV/Arrow/Quandl | Bundle格式 | CSV/Pandas |
| 手续费/滑点模拟 | 内置Blotter | 内置 | 内置 |
| 分析工具对接 | Pyfolio/Alphalens | Pyfolio | 需自行对接 |
| 项目维护状态 | 社区维护中 | 已停止更新 | 社区维护中 |
从对比可以看出,Spectre在速度和ML集成方面有明显优势,但在生态成熟度和维护活跃度上还有差距。选择哪个工具,取决于你的具体需求和硬件条件。
九、Spectre的五大优势
用了这么久,我把Spectre最核心的几个优势总结一下:
1. 速度碾压,没有对手
GPU加速带来的速度提升是实实在在的。77倍的加速比意味着你原来等一个下午的结果,现在几分钟就能拿到。研究效率的提升直接转化为策略迭代的效率,最终体现在业绩上。
2. 硬件成本低,性价比高
一张消费级RTX 3090/4090就能跑起来,不需要昂贵的云计算集群。个人投资者和中小团队都能负担得起,把原来只有大机构才有的算力拉到了普通人的桌面。
3. 生态兼容,无缝衔接
基于PyTorch,天然对接深度学习生态;兼容Pyfolio和Alphalens,从因子研究到绩效分析一条龙。不需要在不同工具之间反复切换,研究流程顺畅很多。
4. 开源免费,没有锁定
MIT协议开源,代码透明,可以自由修改和扩展。对于有定制化需求的团队来说,这意味着不会被困在任何商业软件的生态里。
5. 前视偏差防护,回测更可信
DAG因子引擎自动处理依赖关系和时序偏移,减少了人为失误导致回测失真的风险。在量化研究中,一个没有偏差的回测结果比一个漂亮但失真的结果重要一百倍。
十、客观说缺点:Spectre的六个短板
说完好的,也得说说不足。做决策必须全面了解,不能只听好话。
| 短板 | 具体表现 | 影响程度 |
|---|---|---|
| GPU硬件依赖 | 没有NVIDIA显卡就只能用CPU,速度优势归零 | 高 |
| 维护节奏偏慢 | 最近一次大版本更新在2020年,后续主要是小修小补 | 中高 |
| 数据格式有限 | 对tick级等非标数据格式支持不足,需自写Loader | 中 |
| 学习门槛不低 | 需要Python+量化+GPU编程基础,新手入门有难度 | 中 |
| 超大规模受限 | 万只以上标的的因子计算会遇到显存瓶颈,原生不支持分布式 | 中 |
| 缺少企业级特性 | 无合规检查、无实盘接口,不适合直接用于生产环境 | 中低 |
特别提醒
维护节奏是最值得关注的点。量化领域数据标准和监管要求变化很快,一个长期不更新的工具可能在新环境下出现兼容性问题。建议在生产使用前做好充分测试,关注社区动态。
十一、实际应用场景:谁适合用Spectre?
说了这么多优缺点,那到底谁该用Spectre?我按场景拆一下:
场景A:量化投研团队
如果你是做因子研究的投研团队,每天需要测试大量因子组合,Spectre的GPU加速能把研究效率提升一个量级。特别是在市场波动加大的时候,快速迭代因子策略的能力就是竞争力。
场景B:个人量化开发者
手里有一张RTX显卡的独立研究者,Spectre让你在家就能拥有接近机构级别的回测能力。配合yfinance免费数据,零成本搭建专业量化研究环境。
场景C:AI+量化融合团队
PyTorch基因让Spectre成为AI因子研究的天然平台。你可以直接在因子计算流程中嵌入神经网络模型,实现传统因子和AI因子的混合研究,这是传统量化库做不到的。
场景D:风险管理与压力测试
不只是做策略,Spectre的高性能也适合做大规模风险模拟。比如模拟不同市场环境下的组合表现,评估极端行情下的风险敞口,这些场景都需要大量计算。
老余建议
如果你只是做简单的策略验证,Zipline或Backtrader就够用了。但如果你需要处理大规模数据、高频因子计算、或者想把ML融入量化流程,Spectre值得认真尝试。从小的数据集开始跑,验证效果后再逐步扩大规模。
十二、未来展望:GPU量化生态会走向哪里?
站在更大的视角看,Spectre代表的GPU加速量化只是开始。随着GPU算力持续增长(RTX 5090已经箭在弦上)、显存越来越大、CUDA生态越来越完善,量化研究的计算范式正在发生根本性变化。
几个值得关注的趋势:
趋势一:GPU将成为量化研究的标配。就像10年前GPU改变了深度学习一样,它正在改变量化研究的方式。未来不会用GPU加速的量化团队,就像今天还在用CPU训练神经网络一样低效。
趋势二:AI因子将成为主流。传统因子挖掘靠人工,效率低、覆盖窄。用神经网络自动发现因子,再用GPU高速验证,这个闭环会越来越成熟。Spectre的PyTorch基础让它在这个方向上有天然优势。
趋势三:开源量化生态会加速成熟。Spectre虽然有维护节奏的问题,但它证明了GPU量化工具的可行性。未来一定会有更多类似的开源项目出现,功能更完善、社区更活跃。
写在最后
Spectre作为一个基于PyTorch的GPU加速量化库,在因子计算和策略回测上展现出了碾压级的速度优势,RTX 3090上最高可达77倍提速。它的DAG因子引擎确保计算逻辑正确,CUDA并行计算榨干显卡算力,与ML生态无缝衔接打开了AI因子的想象空间。但GPU依赖、维护节奏偏慢、数据格式局限等问题也需要理性看待。
工具永远是手段,策略才是核心。再快的计算速度,也救不了一个逻辑有问题的策略。但一个好策略配上足够快的验证工具,确实能帮你更快地找到对的方向。
建议感兴趣的朋友从小数据集开始尝试,一步步验证效果。Spectre的GitHub仓库里有详细的文档和示例,足够你上手了。
- Spectre基于PyTorch,支持GPU加速,因子计算提速最高77倍。
- DAG有向无环图确保因子计算顺序正确,自动防护前视偏差。
- 支持自定义因子、完整回测流程,兼容Pyfolio和Alphalens。
- 可与深度学习模型无缝集成,拓展AI驱动因子的可能性。
- 需注意GPU硬件依赖、项目维护节奏偏慢及数据格式限制。
风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。
版权声明:本文为原创内容,转载请注明出处。
#量化交易 #GPU加速 #Spectre #因子分析 #回测 #PyTorch #开源工具 #Python #RTX3090 #深度学习 #策略研究 #金融科技
Be First to Comment