作 者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:这篇文章记录了我从零构建AMPE(自适应市场压力引擎)指标的完整过程。还用了2449只股票全量回测只有24.3%跑赢持有,但这个比挑40只股票然后说100%胜率有价值,因为失败数据可证伪可信。
我拿自己新做的指标跑了一遍全量测试,2449只股票,只有595只跑赢了持有策略。胜率24.3%。
你可能会想:这指标不行啊。但我想说:这恰恰说明它没过拟合。一个号称在90%的股票上跑赢持有策略的指标,要么在撒谎,要么在曲线拟合。真正有效的策略都有自己的”主场”:它只在特定的市场状态下、特定类型的股票上才有效。24.3%的胜率告诉我:AMPE有真实的边际优势,只不过这个优势是有边界的。
而且在1854只股票上失败这件事,是我做过的最有用的工作。下面我一步步拆解,讲清楚这个指标怎么来的、怎么工作的、以及那些失败教会了我什么。

一、为啥要做AMPE
大多数技术指标都是围绕单一概念设计的。RSI(相对强弱指标)测动量,ATR(真实波幅均值)测波动率,EMA(指数移动均线)测趋势方向。它们简洁、好理解,这很有用。
但问题是,市场从来不是只在一个维度上运动的。一只股票可以同时出现这三种情况:趋势向上、波动率在收缩、价格正在扫过流动性密集区。单一指标只能看到其中一个画面,就像只通过一扇窗户看整栋楼的状况,你看到的永远不完整。
我想做一个能”读懂整个房间”的指标:把多种市场压力合成一个振荡器,但不是简单粗暴地取平均,而是根据当前市场处于什么状态,智能地调整各维度的权重。
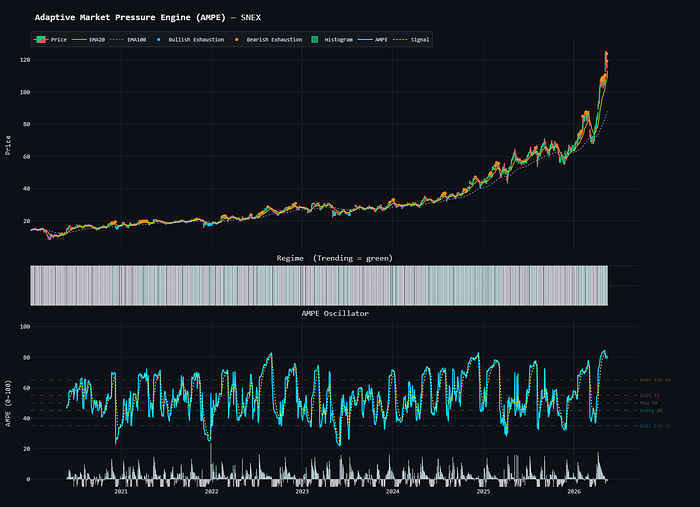
AMPE指标效果图
这就是AMPE:自适应市场压力引擎。有4个压力分量、1个实时状态检测器、以及在趋势行情和震荡行情之间自动切换的自适应权重。
二、四大压力分量详解
AMPE每一根K线的输出值,都是4个归一化压力读数的加权和,每个分量捕捉市场行为的不同维度。

1. 趋势压力(Trend Pressure)
把EMA间距和EMA斜率组合在一起,都用ATR做归一化处理。这样算出来的趋势读数,不受股票绝对价格或波动率大小的影响:一只50美元的股票和一只500美元的股票,趋势压力值在同一个尺度上比较。
2. 动量压力(Momentum Pressure)
把短期变动率(ROC)和中期的中心化RSI偏移值混合在一起。简单说就是:价格变化的速度有多快,加上相对历史来说当前动能是强还是弱。一个看短期加速度,一个看中期位置。
3. 流动性压力(Liquidity Pressure)
这是最有意思的一个分量。它统计一个滚动窗口内多头扫荡和空头扫荡的次数:
- 多头扫荡:K线下影线刺穿前期低点,但收盘价回到了前期低点之上——有人在下面吸收了卖压
- 空头扫荡:K线上影线刺穿前期高点,但收盘价回到了前期高点之下——有人在上面吸收了买压
净差额告诉你当前谁在主导流动性博弈。这个分量的直觉很明确:价格”假装”突破一个位置然后收回来,往往意味着反方向有大资金在承接。
4. 压缩压力(Compression Pressure)
把当前ATR和它的长期均值做比较。当今天的波动率远低于历史平均水平,说明市场正在”憋气”——能量在蓄积, breakout可能不远了。压缩不会告诉你方向,但告诉你”快出大动静了”,这个信息本身就很有价值。
为什么归一化是底线?
每个分量在合成之前都必须归一化到[0, 1]区间。如果不做归一化,变动率(ROC)这种天然波动大的分量会直接吞掉其他所有分量的信号——你的”合成振荡器”其实只是ROC的马甲。归一化之后,每个分量对最终结果的贡献只取决于你给它的权重,而不是它自身的数值范围。
三、状态检测器:让指标”适应”市场
AMPE最核心的创新是状态检测器。它在每一根K线上做一次判断:当前趋势强度是否高于过去N根K线的历史中位数?如果是,判定为趋势行情;如果不是,判定为震荡行情。
然后权重会根据当前状态自动切换:
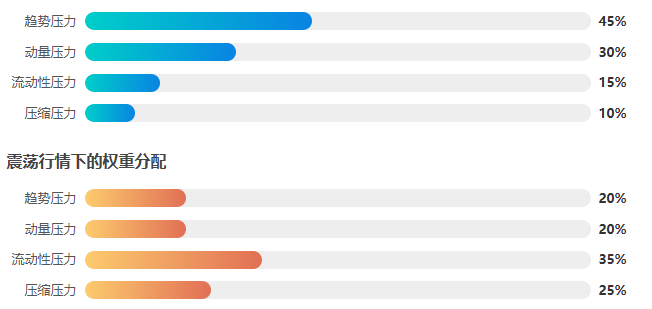
这个切换的直觉很清晰:趋势行情里,趋势和动量是主导力量,给它更高的发言权;震荡行情里,价格来回扫荡流动性、波动率在压缩,那流动性压力和压缩压力就变得更重要。
一个关键的好处是:同一个指标不会把趋势跟踪的滤镜硬套在一只横盘了半年的股票上。振荡器适应市场现在的样子,而不是你希望它成为的样子。
| 市场状态 | 趋势压力 | 动量压力 | 流动性压力 | 压缩压力 |
|---|---|---|---|---|
| 趋势行情 | 45% | 30% | 15% | 10% |
| 震荡行情 | 20% | 20% | 35% | 25% |
状态切换为什么比固定权重强?
固定权重下,AMPE只是一个”看起来还不错”的振荡器。加上状态切换之后,它变成了一个策略。这是整个开发过程中性能提升最大的一步——不是靠调参数,而是靠让指标在正确的时机关注正确的维度。
四、耗竭检测:避免追高杀跌
在振荡器之上,我又加了一层基于背离信号的耗竭检测器。
空头耗竭信号:价格收盘价创出新高,但RSI正在转头向下,经典的动量背离,同时AMPE值已经超过了空头耗竭阈值。这意味着虽然价格还在往上走,但推动它上升的动能已经在衰减,就像汽车踩着油门但速度提不上去了。
多头耗竭信号:镜像逻辑。价格创出新低,RSI却在回升,同时AMPE低于多头耗竭阈值。
这些信号直接输入到策略的进出场逻辑里,给策略一个”不要追已经跑不动的行情”的机制。说白了就是:当市场看起来还在冲,但内部动能已经跟不上了,耗竭检测会提醒你是该收手了。
五、全量测试:2449只股票,不挑不拣
指标搭好之后,我做了一次全量测试。不挑股票,不做筛选,2449只全部跑一遍。执行条件如下:
- 信号触发后,以下一根K线开盘价执行;
- 手续费0.1%,滑点0.2%;
- 每只股票使用其全部可用历史数据;
- 前向优化(WFO)滚动验证,杜绝过拟合。
结果:2449只股票中,595只在扣除成本后跑赢了持有策略。大约四分之一。
如果一个在90%的股票上跑赢持有策略的指标,要么在说谎,要么已经过拟合了。真实的策略都有”主场”:它只在特定的市场状态下、在特定类型的股票上有效。24.3%的胜率告诉我:AMPE有真实的边际优势,只不过这个优势是有边界的。
在1854只股票上失败,不是白费功夫。它是一张信号地图,精确告诉你,一个动量自适应策略在哪里有效,在哪里无效。这比精挑细选40只股票然后宣称100%跑赢,可信得多。

40只股票深度验证结果图表
全量测试之后,我又做了一组精选验证——40只横跨不同行业、时间跨度从1977年到2026年的股票。这40只全部跑赢了持有策略。几个亮眼的个案:
| 股票代码 | 公司名称 | 测试区间 | 策略收益 | 持有策略收益 | 超额收益 |
|---|---|---|---|---|---|
| BCPC | Balchem Corp. | 1990-2026 | 201,711% | 121,211% | +80,500% |
| REGN | Regeneron | 1995-2026 | 61,766% | 21,159% | +40,607% |
| SNEX | StoneX Group | 1999-2026 | 59,909% | 33,407% | +26,502% |
| DIOD | Diodes Inc. | 1977-2026 | 68,243% | 44,877% | +23,366% |
| MYE | Myers Industries | 1984-2026 | 11,913% | 5,569% | +6,344% |
这40只股票的单次信号胜率在68%到95%之间。
如何看这组精选数据?
精选40只全部跑赢,听起来很漂亮。但别忘了,全量测试只有24.3%。精选验证集证明的是”在合适的股票上,这个策略确实有效”,而不是”这个策略对任何股票都有效”。两者的区别很重要——前者是事实,后者是幻想。
六、开发过程中的五个核心教训
教训一:归一化没有商量余地
不归一化,合成的振荡器就只是噪声最大的那个分量的替代品。ROC天生波动幅度大,如果不把它压到[0,1]区间,最终结果几乎就等于ROC稍微加了一点其他东西的影子。归一化是让四个分量”公平对话”的前提。
教训二:状态切换权重值得那份复杂度
整个开发过程中,性能提升最大的一步就是加入状态检测器。固定权重做出来的是一个”还算好用的振荡器”,加上自适应权重之后才变成一个”能跑策略的工具”。复杂度换来了质的飞跃,这笔账很划算。
教训三:前向优化防止”漂亮的谎言”
每次我在早期项目里跳过前向优化(WFO),回头去验证的时候,所谓”优化后的参数”都是过拟合的产物。WFO的核心做法是把历史数据切成训练集和测试集,滚动前移,在训练集上找参数,在测试集上验证,循环往复。只有通过了WFO的参数,才敢拿到实盘上用。
# 前向优化(WFO)核心逻辑伪代码def walk_forward_optimization(data, train_period, test_period): results = [] for i inrange(total_windows): # 训练窗口:寻找最优参数 train_data = data[i : i + train_period] best_params = optimize(train_data) # 测试窗口:用最优参数做样本外验证 test_data = data[i + train_period : i + train_period + test_period] oos_result = backtest(test_data, best_params) results.append(oos_result) return results # 只看样本外结果教训四:流动性扫荡分量被严重低估了
开发过程中我差点把流动性压力这个分量砍掉。但后来发现,在震荡行情里,趋势和动量分量几乎都接近中性,这时候流动性扫荡就成了最重要的区分信号。它识别的是”谁在关键位置吸收了筹码”,这种信息在震荡市里比趋势信号有用得多。
教训五:证据的数量胜过单一结果的信心
2449只股票上24.3%的胜率,是一个真实的、可证伪的声明。任何人都可以拿自己的数据复现、挑战、改进它。但”精挑40只股票100%跑赢”这种结论,没法被证伪,因为你永远可以质疑样本选取的偏见。做量化,可证伪比可吹嘘重要一百倍。
七、从”做指标”到”做策略”:思维转变
回头看整个开发过程,我觉得最大的思维转变不是技术上的,而是心态上的。
做指标的人很容易陷入一个陷阱:不断调参数,让结果在越来越多的股票上”看起来不错”。但真正的进步来自于反向操作,承认你的策略只在特定条件下有效,然后把精力花在精确定义那些条件上。
AMPE在76%的股票上跑输持有策略,这个数字不是丢脸的事,而是一张精确的”适用性地图”。它告诉我:
- 动量自适应策略对趋势性和波动性适中的股票效果最好;
- 对长期横盘或剧烈震荡的品种,这个策略不适用;
- 状态检测器能帮你识别当前属于哪种环境;
- 知道什么时候不用这个策略,比知道什么时候用更重要。
就像我一直说的:在量化交易里,知道自己不知道什么,远比相信自己什么都知道更有价值。
八、给想自己做指标的朋友几点建议
- 先归一化,再合成。没有归一化的多分量合成,就是让噪声最大的分量做主。
- 让指标适应市场,而不是让市场适应指标。状态切换比固定参数更复杂,但回报也更大。
- 全量测试,不挑不拣。先跑1000只以上再说,没跑过全量测试的策略不叫策略,叫故事。
- 前向优化是唯一的诚实检验。跳过WFO的回测结果,一律视为过拟合产物。
- 重视失败数据。知道策略在哪里不工作,比知道它在哪里工作更有指导意义。
风险提示:最后,这篇文章仅为信息分享与学习交流之用,不构成任何投资建议。所有回测结果均基于历史数据,使用前向优化方法产生,历史表现不代表未来收益。投资有风险,入市需谨慎。
版权声明:本文为原创内容,转载请注明出处。
#自适应指标 #量化交易 #市场状态识别 #AMPE #回测验证 #Walk-Forward #流动性扫描 #波动率压缩 #动量策略 #技术指标开发
Be First to Comment