作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:今天聊一个为数不多能让我看后能深度测试并用于生成端的项目:清华Kronos,号称全球首个金融K线基础模型。它用120亿根K线预训练,把K线当语言来"读"。让我来拆解它的核心原理和实战用法,分享给你。
上个月刷GitHub热榜,一个项目的定位吸引了了我:专门训练来读懂股市K线的AI。不是通用大模型,不是写文章画图的那种,是专门喂K线数据、只干金融这一件事的。
目前这篇论文已经被AAAI 2026收录了,AI领域顶会,含金量不用我多说。
今天我就把这个项目从头到尾拆一遍:它到底做了什么,技术有多硬核,怎么上手用,以及它背后更大的趋势意味着什么。

① Kronos到底做了什么?
一句话版本:Kronos是全世界第一个专门为金融K线设计的开源基础模型。
什么叫”基础模型”?就是像GPT之于自然语言、BERT之于文本理解那样,先在海量数据上做预训练,学会通用的”理解能力”,然后再针对具体任务微调。
但过去,金融领域一直没有这样的基础模型。
原因很简单:金融数据噪声太大、非平稳性太强,通用时序模型搬过来水土不服,甚至性能还不如不预训练。
清华团队的Kronos,就是来填这个坑的。
它是一个Decoder-Only的Transformer模型,预训练数据来自全球45家交易所的K线历史,横跨7种时间周期(1分钟到1天),总共120亿根K线,这个规模在金融时序领域是史无前例的。
K线是做量化的人每天盯着的东西。传统量化要做特征工程,要人工设计指标:均线、布林带、MACD、RSI……一条一条去试。
Kronos干的事是:把K线当成一种语言,让模型自己学出什么模式最有效。
② 核心架构:两阶段框架,让K线变”语言”
这是Kronos最核心的创新,也是整篇论文的精华所在。它采用了一个两阶段框架:
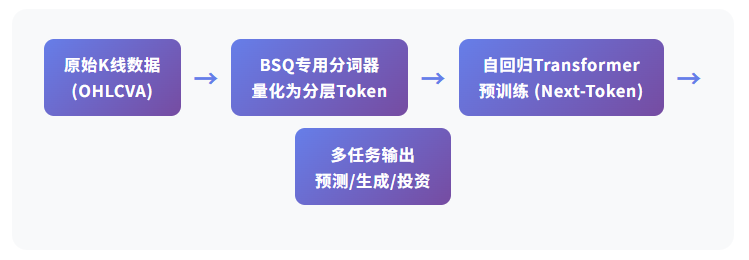
第一阶段:BSQ分词器:把K线变成”词”
自然语言处理里,GPT用BPE分词器把文本切成token。Kronos也做了类似的事,但对象不是文字,而是连续的K线数据。
它用了一种叫二进制球面量化(Binary Spherical Quantization,BSQ)的技术,将连续的K线数据量化为离散的、分层结构的token序列。
具体来说,每根K线的OHLCVA(开盘价、最高价、最低价、收盘价、成交量、成交额)6个维度,都会被编码成一个独立token,而这个token又包含粗粒度(Coarse)和细粒度(Fine)两个子token。
为什么要分粗细?
因为市场波动有层次:粗粒度捕捉大趋势,细粒度捕捉小波动。这就好比你看行情,既要看日线的大方向,也要看分钟线的细节,两个层面缺一不可。
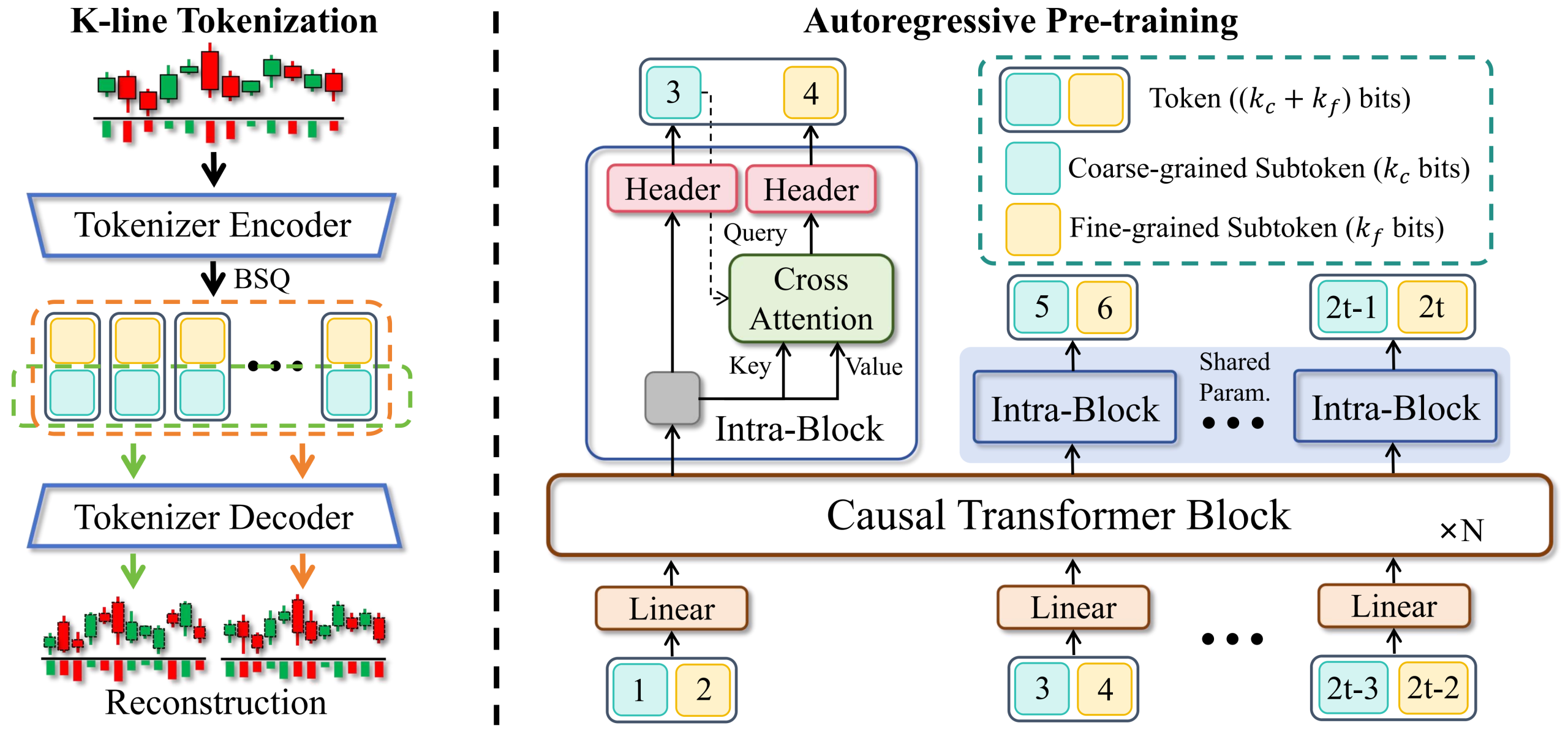
Kronos分词器架构图:K线数据经过BSQ量化为粗粒度与细粒度双组分分层Token
第二阶段:自回归Transformer:学会说”股市的话”
有了token之后,Kronos使用一个大型自回归Transformer(Causal Transformer)在这些token上进行预训练。训练目标就是GPT那一套:Next-Token Prediction——根据前面的token序列,预测下一个token。
但这里有个关键区别:因为token是分层结构的(粗+细),模型需要顺序预测分层子token,先预测粗粒度部分,再预测细粒度部分。这种设计让模型能同时捕捉宏观趋势和微观波动,而且通过交叉注意力机制实现不同时间尺度特征的融合。
简单总结:K线被转成”词”,模型在这些”词”上学会了说”股市的话”。整个思路跟GPT学习自然语言是一脉相承的,但专门为金融数据的特性做了深度适配。
有人会问,为什么不直接用通用时序模型?
答案是:金融数据的信噪比极低,通用模型在预训练阶段看到的金融数据占比太少,学不到有效的金融模式。Kronos从一开始就只为金融K线服务,这是它的核心优势。
③ 模型家族:从4.1M到499.2M
Kronos提供了一组不同规模的模型,让你根据自己的算力和需求灵活选择:
| 模型 | 配套分词器 | 上下文长度 | 参数量 | 开源 |
|---|---|---|---|---|
| Kronos-mini | Kronos-Tokenizer-2k | 2048 | 4.1M | 已开源 |
| Kronos-small | Kronos-Tokenizer-base | 512 | 24.7M | 已开源 |
| Kronos-base | Kronos-Tokenizer-base | 512 | 102.3M | 已开源 |
| Kronos-large | Kronos-Tokenizer-base | 512 | 499.2M | 暂未开源 |
几个要点说明一下:
- Kronos-mini虽然只有4.1M参数,但上下文窗口达到了2048,是所有模型中最长的。轻量级部署场景首选。
- Kronos-small/base上下文为512,使用时输入的历史数据长度(lookback)不要超过这个值,模型会自动截断超长部分。
- 所有开源模型都在Hugging Face上可直接下载,模型名称以NeoQuasar开头。
- Kronos-large暂未开源,但看参数量499.2M,应该是最强版本,期待后续开放。
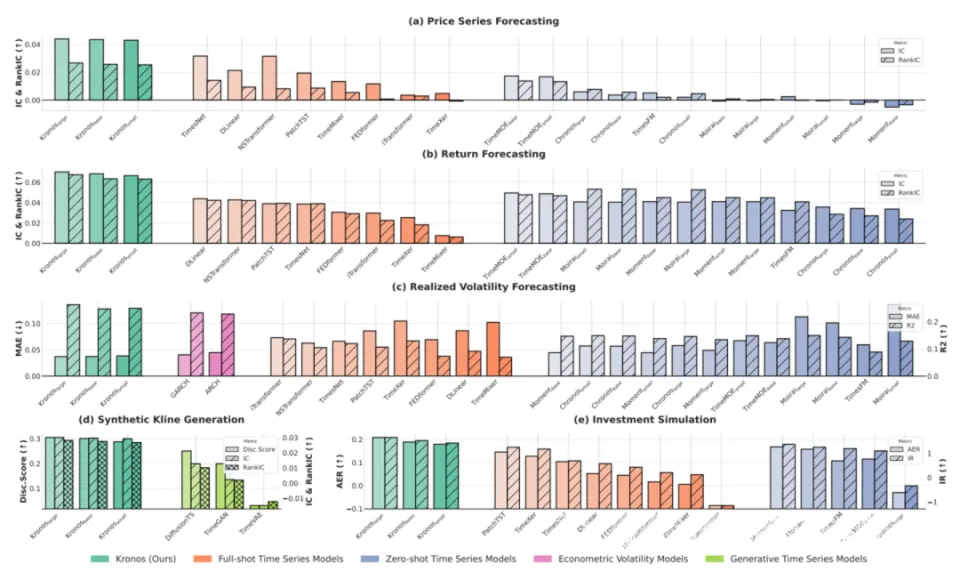
Kronos模型在三大预测任务(价格预测、收益预测、波动率预测)上的性能对比图
④ 效果到底怎么样?
光说架构不聊效果都是耍流氓。Kronos的论文给出了非常扎实的实验数据:
| 任务维度 | 评估指标 | 性能提升 |
|---|---|---|
| 价格预测 | RankIC | 跃升93% |
| 收益预测 | IC | 提升40% |
| 波动率预测 | MAE | 降低9% |
在价格预测任务上,RankIC跃升93%:这意味着模型对价格排序的判断能力有了质的飞跃。收益预测IC提升40%,波动率预测MAE降低9%,也都是非常显著的改进。
腾讯新闻《清华KRONOS开源》
https://new.qq.com/rain/a/20250925A06QIS00
而且,Kronos有一个非常强的特性:卓越的零样本性能。
什么意思?就是你不需要在目标市场做任何微调,模型直接就能给出不错的结果。它用全球45个交易所的数据预训练,学到的模式有很强的泛化能力:无论是美股、A股还是加密货币,它都能直接上手。
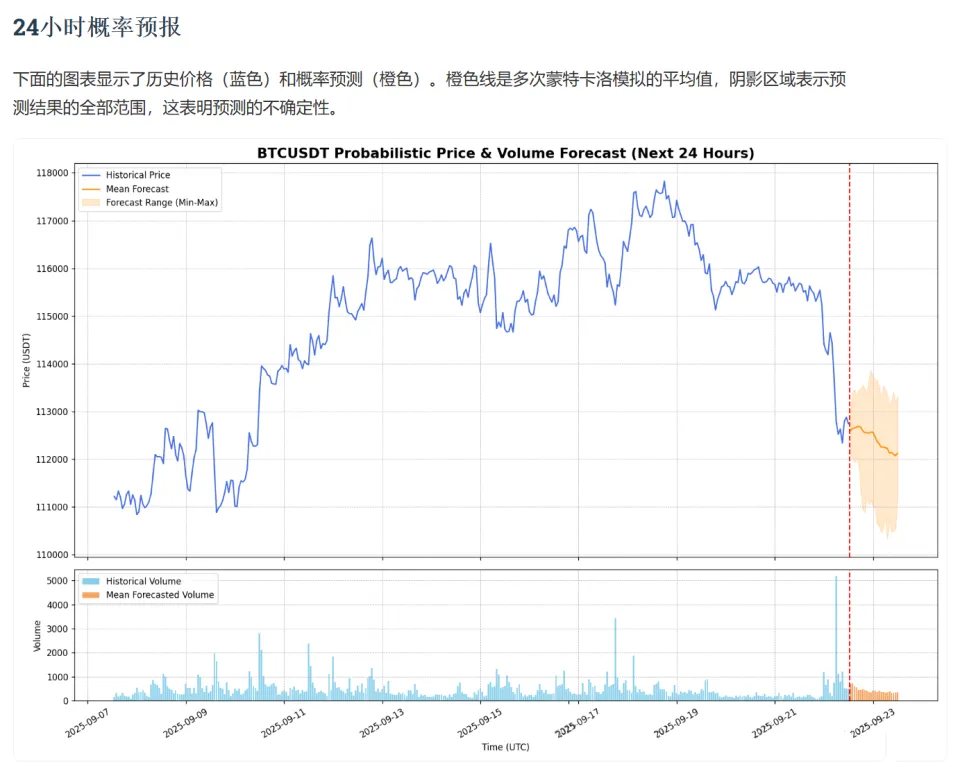
团队还提供了在线Demo,可以看BTC/USDT未来24小时的走势预测结果。感兴趣的自己去体验:
在线Demo:BTC/USDT 24小时预测
https://shiyu-coder.github.io/Kronos-demo
⑤ 手把手教你用:从安装到预测
说了这么多,能不能上手跑起来才是关键。好消息是,Kronos的接口封装得非常简洁,几行代码就能出结果。
5.1 环境安装
首先确保Python 3.10+,然后安装依赖:
# 克隆项目git clone https://github.com/shiyu-coder/Kronos.git cd Kronos# 安装依赖 pip install -r requirements.txt5.2 加载模型与分词器
从Hugging Face Hub加载预训练模型:
from model import Kronos, KronosTokenizer, KronosPredictor# 加载分词器和模型tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")model = Kronos.from_pretrained("NeoQuasar/Kronos-small")5.3 初始化预测器
# 初始化预测器,指定上下文窗口长度predictor = KronosPredictor(model, tokenizer, max_context=512)5.4 准备数据
预测器需要三个输入:
- df:包含历史K线数据的DataFrame,必须包含
open, high, low, close列,volume和amount为可选 - x_timestamp:历史数据对应的时间戳
- y_timestamp:你想预测的未来时间段的时间戳
import pandas as pd# 加载数据df = pd.read_csv("./data/XSHG_5min_600977.csv") df['timestamps'] = pd.to_datetime(df['timestamps'])# 定义回看窗口和预测长度lookback = 400 pred_len = 120# 准备预测器输入x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp = df.loc[:lookback-1, 'timestamps'y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps']5.5 生成预测
# 生成预测结果pred_df = predictor.predict( df=x_df, x_timestamp=x_timestamp, y_timestamp=y_timestamp, pred_len=pred_len, T=1.0, # 采样温度 top_p=0.9, # 核采样概率 sample_count=1 # 生成路径数量(可多条取平均)) print("预测结果:")print(pred_df.head())实战提示:sample_count参数很有意思。设为1就是单次采样,设大一点(比如10)就是生成多条预测路径然后取平均,可以降低随机性。做概率预测的时候这个参数很实用。另外,温度T越低,输出越确定;T越高,输出越随机多样。
5.6 批量预测
如果你要同时对多只标的做预测,Kronos提供了 predict_batch 方法,利用GPU并行计算提升效率:
# 准备多个数据集df_list = [df1, df2, df3]x_timestamp_list = [x_ts1, x_ts2, x_ts3]y_timestamp_list = [y_ts1, y_ts2, y_ts3]# 批量预测pred_df_list = predictor.predict_batch( df_list=df_list, x_timestamp_list=x_timestamp_list, y_timestamp_list=y_timestamp_list, pred_len=pred_len, T=1.0, top_p=0.9, sample_count=1,注意:批量预测要求所有序列的历史长度(lookback)和预测长度(pred_len)必须一致,每个DataFrame必须包含open, high, low, close列。volume和amount缺失时会自动填零。
5.7 可视化Demo
项目提供了完整的预测+可视化脚本,位于 examples/prediction_example.py。运行后会生成一张对比图,展示真实走势与模型预测的对比。
另外还有一个不需要成交量和成交额数据的脚本:examples/prediction_wo_vol_example.py,只有OHLC也能跑。
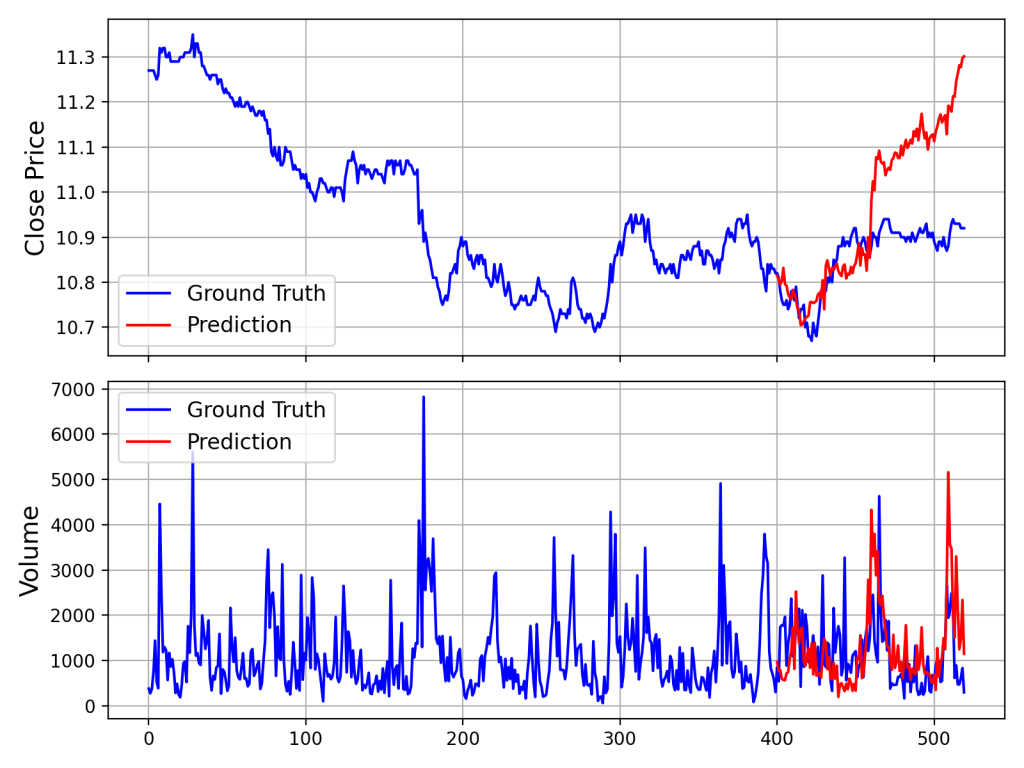
Kronos预测效果对比图:真实走势 vs 模型预测
⑥ A股微调实战:从Demo到生产
预训练模型虽好,但你想在自己的数据上做微调才能发挥最大价值。Kronos提供了一套完整的微调流水线,以A股市场为例,我来教你用Qlib准备数据、微调模型、做回测。
免责声明:这条流水线是一个演示,不是生产级量化系统。真正稳健的量化策略需要组合优化、风险因子中性化等更多技术。本文仅做技术分享,不构成任何建议。
6.1 安装Qlib
pip install pyqlib然后按照Qlib官方指南下载和设置本地数据。
6.2 四步走流水线
- Step 1:配置实验:修改
finetune/config.py中的路径和超参数,包括Qlib数据路径、数据集保存路径、模型检查点路径、预训练模型路径等。 - Step 2:准备数据→运行
finetune/qlib_data_preprocess.py,从Qlib目录加载原始行情数据,处理后分成训练/验证/测试集,保存为pickle文件。 - Step 3:微调模型分两阶段:先微调分词器
train_tokenizer.py,再微调预测器train_predictor.py 。两个脚本都支持多GPU训练,用torchrun启动。 - Step 4:回测评估:运行
finetune/qlib_test.py,加载模型推理,生成信号,运行简单的Top-K策略回测。
6.3 微调命令示例
# 微调分词器(2卡示例)torchrun --standalone --nproc_per_node=2 finetune/train_tokenizer.py# 微调预测器(2卡示例)torchrun --standalone --nproc_per_node=2 finetune/train_predictor.py# 回测评估python finetune/qlib_test.py --device cuda:0实战要点:微调分词器是为了让BSQ量化更适配你的数据分布;微调预测器才是提升预测精度的关键。两者顺序不能反,先调分词器再调预测器。
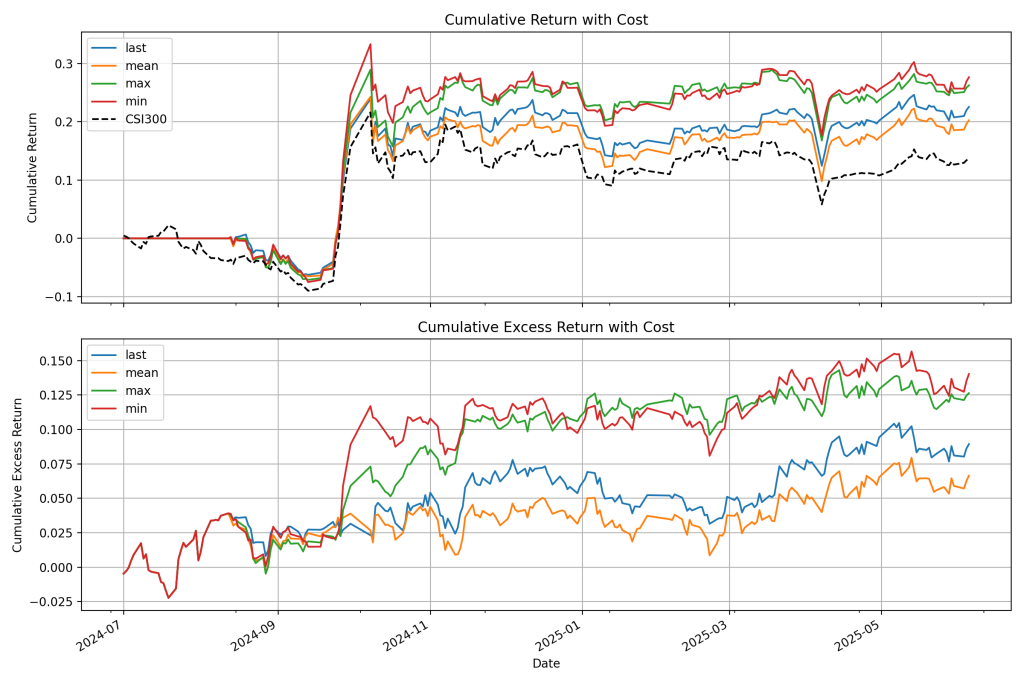
A股微调回测示例:累计收益曲线对比
⑦ 从Demo到生产:关键注意事项
Kronos的Demo和微调脚本看起来很香,但如果你想把它用到实盘级别,有几个核心问题必须想清楚:
- 原始信号 ≠ 纯Alpha:模型输出的预测信号是”原始信号”,还没经过任何风险处理。在真实的量化流程中,这些信号需要送入组合优化模型,对冲掉市场Beta、风格因子等常见风险暴露,才能提取出”纯Alpha”。直接用原始信号做决策,跟裸奔差不多。
- 数据适配:项目里的QlibDataset只是个示例,换成你自己的数据源,加载和预处理的逻辑都得改。不同数据格式的对齐、缺失值处理、复权方式,都会影响最终效果。
- 策略复杂度:示例里用的是简单Top-K策略,这只是起点。生产级策略要考虑组合构建、动态仓位管理、风控规则(止损/止盈逻辑),回测也要精细建模交易成本、滑点和市场冲击。
- 模型局限性:Kronos是概率预测模型,输出的是采样结果,不是确定性答案。温度参数、采样次数、Top-P值都会影响结果的稳定性和多样性,需要反复调试验证。
实战提醒:Kronos是一个研究级工具,不是一键致富的按钮。任何模型在实盘中的表现都可能和回测差异巨大,请务必保持敬畏之心,做好充分的风险评估。
⑧ 技术深挖:BSQ量化到底怎么工作的?
前面我用比较通俗的方式讲了BSQ分词器的原理,这里给想深入的朋友再展开一下。
BSQ全称Binary Spherical Quantization(二进制球面量化),它的核心思想是:把连续的潜在向量投影到可学习的超平面上,通过判断向量落在超平面的哪一侧,得到一个二进制编码。多层超平面叠加,就能形成层次化的离散表示。
在Kronos中,每根K线的6维OHLCVA数据,经过编码器映射到潜在空间后,会被BSQ量化为两组子token:
| 子Token类型 | 粒度 | 捕捉的信息 | 类比 |
|---|---|---|---|
| Coarse Token | 粗粒度 | 大趋势、大方向 | 日线级别的趋势判断 |
| Fine Token | 细粒度 | 小波动、微观结构 | 分钟级别的细节变化 |
这种分层设计的好处是显而易见的:模型在预测时,可以”先定方向、再定细节”,既不会迷失在大方向上,也不会丢失微观信息。这跟人类看盘的逻辑是一样的:先看大趋势在哪,再找具体的进出场时机。
而自回归Transformer的训练目标,就是在给定前面所有token的条件下,依次预测下一个粗粒度子token和细粒度子token。通过交叉注意力机制,粗细粒度信息能够相互交互和融合,最终形成对市场的完整理解。
老余提示:这种"分词→预训练"的范式跟NLP里GPT的路线高度一致。区别在于,自然语言的token天然是离散的(字、词),而K线的token需要从连续数据中"造"出来。BSQ就是解决这个"造词"问题的核心工具。
⑨ 资源汇总
我把所有相关链接整理在这里,方便大家查阅:
| 资源 | 链接 |
|---|---|
| GitHub仓库 | github.com/shiyu-coder/Kronos |
| 论文(arXiv) | arxiv.org/abs/2508.02739 |
| 在线Demo | Kronos Demo(BTC/USDT预测) |
| Kronos-mini模型 | HuggingFace NeoQuasar/Kronos-mini |
| Kronos-small模型 | HuggingFace NeoQuasar/Kronos-small |
| Kronos-base模型 | HuggingFace NeoQuasar/Kronos-base |
| Tokenizer-base | HuggingFace NeoQuasar/Kronos-Tokenizer-base |
| Tokenizer-2k | HuggingFace NeoQuasar/Kronos-Tokenizer-2k |
| 国内模型托管(始智AI) | wisemodel.cn/NeoQuasar/Kronos-mini |
开源协议:Kronos采用MIT License,商用友好。你可以自由使用、修改和分发,只需保留原始版权声明即可。
⑩ 写在最后
Kronos不只是一个模型,它代表了一种新的思路:让AI真正学会金融市场的”语言”,而不是用通用工具硬套。从BSQ分词器把K线变成”词”,到自回归Transformer学会”续写行情”,整个框架跟GPT处理自然语言的逻辑一脉相承,但每一步都针对金融数据的特性做了深度优化。
作为从业者,我的建议是:不管你现在是做量化还是做AI,都值得花时间研究Kronos,它的技术框架有很强的通用性,完全可以融入你的量化系统中。
我是老余捞鱼,我们下期见。
参考来源:
- GitHub Kronos项目(https://github.com/shiyu-coder/Kronos)
- 腾讯新闻《清华KRONOS开源,K线不是玄学!金融AI迎来GPT时代》(https://new.qq.com/rain/a/20250925A06QIS00)
- arXiv论文(https://arxiv.org/abs/2508.02739)

风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。
版权声明:本文为原创内容,转载请注明出处。
#Kronos #金融AI #K线预测 #开源模型 #量化研究 #清华大学 #AAAI2026 #Transformer #时序基础模型 #金融科技 #HuggingFace #A股
Be First to Comment