作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:过去我们回测策略,很多时候像是带着答案找过程。现在让AI助手遍历所有技术指标及其组合,对目标资产进行“地毯式”回测,然后按“期望收益”自动排名。结果也可能是单个表现平平的指标组合后可能成为王者。这也许改变了策略研发的起点:从“我认为”转向“数据说”。
做量化这些年,我见过太多人把回测当成”编故事大会”。你先拍脑袋想出一个指标,比如RSI,然后指定一个参数14,再挑一个看起来顺眼的股票比如英伟达,最后跑出个还不错的曲线。你很高兴,觉得自己找到了秘诀。
但其实,你只是在自己的世界里打了个转。
这篇文章我想跟你聊的,是怎么跳出这个怪圈。方法说起来很暴力:别只测一个,让AI把你的所有指标、所有参数、所有两两组合全部跑一遍,然后按数学结果自动排名。数据会自己开口,告诉你哪个策略值得多看一眼。
说白了,就是从”假设驱动”转向”数据驱动”。
一、单指标回测的幻觉
之前的文章里,我介绍过怎么用一句话让AI跑回测:
Backtest TSLA with RSI 14 over 3 years这确实方便。但它本质上还是”拿着手电筒找东西”,光照到哪,你就只能看到哪。你根本不知道RSI是不是最好的选择,也不知道14这个周期是不是最优参数。更别提,也许有个你从来没正眼看过的指标,在特斯拉这种高波动资产上表现远超RSI。
心理学上管这叫”确认偏误”。你带着答案找证据,看到的自然都是你想看的。在量化领域,这是最贵的错误。
一个残酷的事实:
手工回测几百个指标和参数组合,一个人要干几个月。但借助AI和向量化回测框架,一杯咖啡的时间就能跑完。所以问题不是”能不能测完”,而是”你有没有意识到需要去测完”。
二、全量扫描,打开全屋的灯
我的解法很简单:让AI遍历所有指标。
我把脚本升级了一下,核心思路是写一个循环,让程序自动测试所有内置技术指标及其常用参数范围。测试完不是简单排个名,而是引入一个关键门槛:交易记录必须不少于5条。
为什么设这个门槛?因为如果三年只触发两三次信号,所谓的”高期望收益”完全是空中楼阁。一次运气不好的波动就能把整个统计结果掀翻。你要的是统计意义,不是彩票奇迹。
另外,排序的核心指标我选的是期望收益(Expectancy),而不是很多人爱看的胜率。这里面的道理很简单:
期望收益 = 胜率 × 平均盈利 − 败率 × 平均亏损
一个胜率90%的策略,如果每次赚1块钱,输一次亏100块,那它依然是亏钱的。期望收益把这个真相直接拍在你脸上,比胜率诚实得多。
指令很简单,就是一句话:
Can you modify python expectancy_skill.py — ticker TSLA — years 3 so it tests every indicator to find the best expectancy for TSLA?程序跑完后,排名表出来了。以下是对特斯拉过去三年数据的单指标扫描结果:
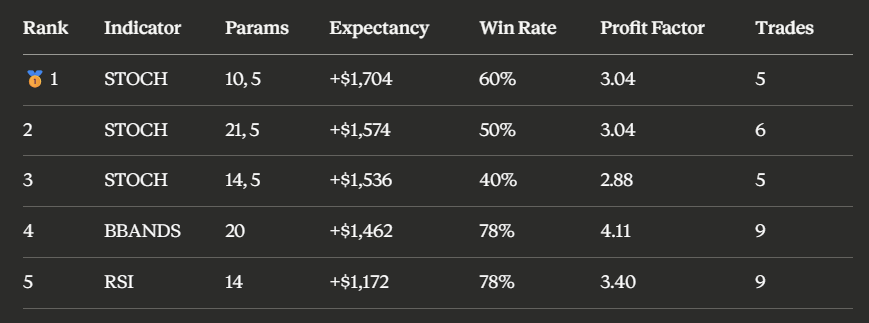
单指标扫描排名数据
看到问题了吗?排名第一的随机指标(STOCH)期望收益最高,但仔细一看,三年只触发了5次。这个频率太低了,结果的稳健性存疑。换句话说,你端着枪三年只开五枪,其中一枪打偏了,整个成绩就大打折扣。
而布林带(BBANDS)和RSI虽然排名靠后一点,但各自触发了9次,胜率也差不多。这就靠谱多了。
一次扫描,不仅告诉你谁表现好,还立刻告诉你谁的表现”信得过”。这才是穷举的价值。
三、把武器库从5个扩充到300个
基础脚本一开始只支持MA、RSI、MACD、布林带和随机指标。但这远远不够。
我让AI把ATR(波动率突破)和OBV(成交量背离)也加进去。只需要一句话,后续每次扫描都会自动带上它们:
Yes, add ATR (volatility-based breakout) and OBV (volume divergence) to the expectancy script.如果你想玩得更大,背后依托的vectorbt框架可以对接TA-Lib等外部库,一次性解锁超过300个技术指标。从动量类到波动类,从趋势类到成交量类,全部覆盖。指令同样简单:
Run the full expectancy sweep on TSLA using all TA-Lib momentum indicators over 3 years.
外部库指标扩展
同一个排名框架,海纳百川。一个指令,几百个指标全部跑完。在手工时代,这活儿够一个实习生干三个月。现在泡杯茶的时间就能搞定。
四、组合才是王炸
单个指标的问题是噪音太多。市场稍微抖一下,假信号就来了。
真正的杀招是组合。两个指标同时满足条件才触发信号,用的是”与”逻辑。门槛提高了,信号少了,但质量往往呈指数级上升。
我让AI跑了一遍所有两两组合。结果如下:
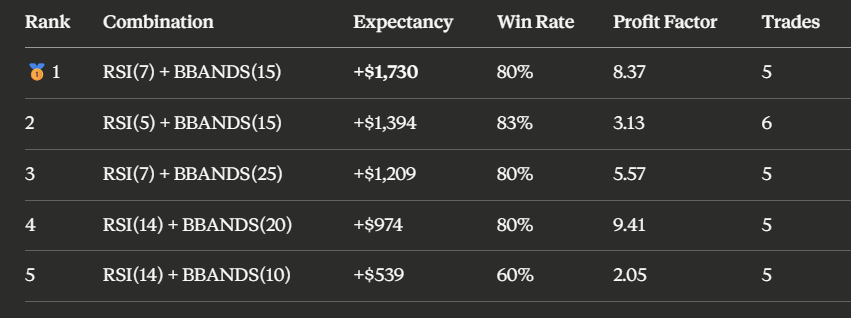
双指标组合排名数据
数据不会说谎。有些组合,靠人类直觉根本猜不到。RSI(7)配合布林带(15),期望收益达到1730美元,这种事拍破脑袋也想不出来。
两个反直觉的发现:
第一,排名前五的全是RSI加布林带的组合。其他指标的混搭根本挤不进来。
第二,单个指标排名里RSI(14)只排第五,表现中规中矩。但把它和布林带(20)组合起来,盈利因子直接飙到9.41。这意味着平均每亏1块钱,能赚回9块4。而随机指标虽然单指标时表现亮眼,一旦进入组合筛选,排名直接崩盘,说明它的兼容性很差,是个”独行侠”。
五、穿透数字,看交易日志
排名表只是起点,不是终点。
看到RSI(14)加布林带(20)表现最好,我立刻让AI把详细交易记录和资金曲线图都调出来:
Give me RSI(14) + BBANDS(20) — TSLA 3yr with the transaction log and chart.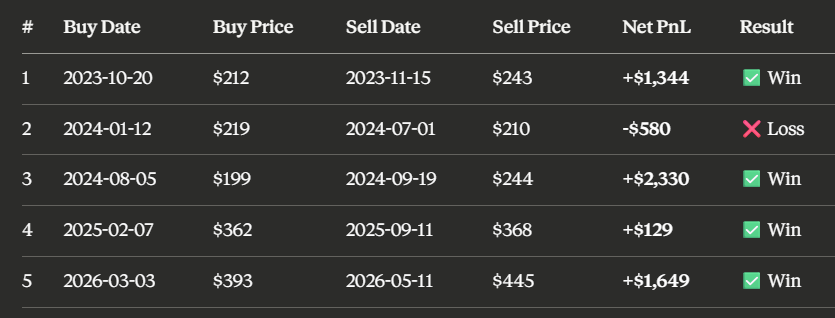
交易日志
三年时间,这个组合一共触发5次信号,其中4次盈利,1次亏损,平均每次期望收益974美元,累计净收益4872美元。
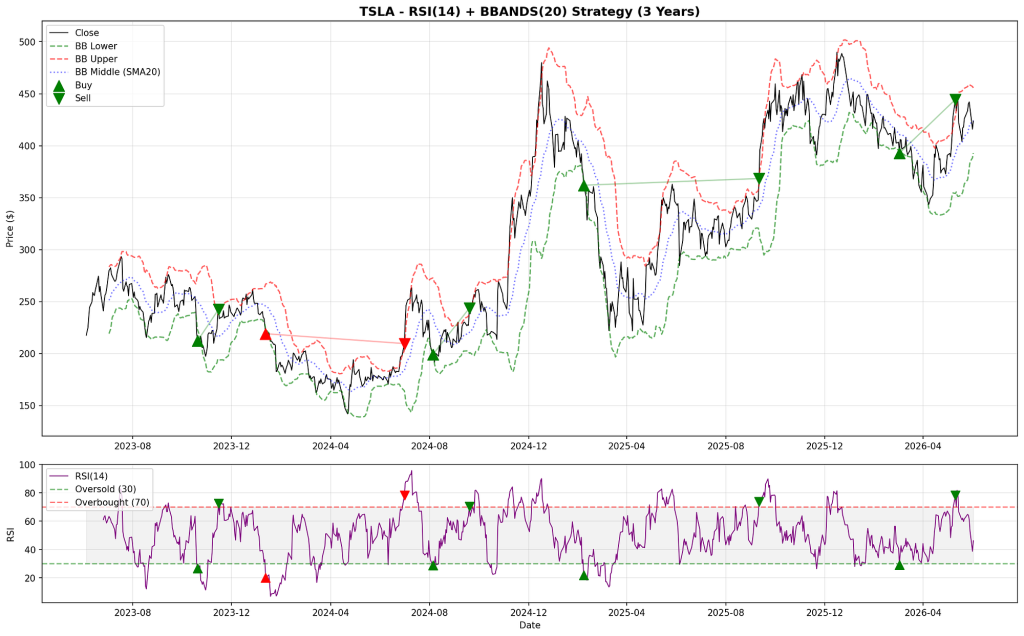
带标注的资金曲线图
看交易日志不是为了自我陶醉,而是为了验证逻辑。每一次进场是在什么位置?离场是因为触及了规则还是指标反转?有没有集中发生在某一段特殊行情里?如果5次盈利里有4次都发生在同一个月,那策略根本经不起时间考验。
数字好看,不如逻辑过硬。这是老余的口头禅。
六、四句话工作流
如果你想在任何资产上复制这套方法,记住这四句指令:
- 扫描全景。 “Test every indicator on [代码] over [N] years and rank by expectancy (minimum 5 trades)” —— 先摸清全貌,别急着下结论。
- 扩充武器库。 “Add [新指标] to the expectancy script, then re-run the sweep” —— 觉得指标不够,随时加,随时扫。
- 组合深挖。 “Run all two-indicator combinations on [代码] over [N] years, minimum 5 trades, ranked by expectancy” —— 让指标互相过滤,找到高含金量的信号。
- 穿透验证。 “Give me [最佳组合] — [代码] [N]yr with the full transaction log and chart” —— 数字背后必须有故事,故事必须经得起推敲。
AI会帮你完成剩下的脏活:下载数据、调用vectorbt跑回测、计算期望收益、生成排名表、画出带标注的曲线图。你要做的,只是读懂结果,然后做决定。
七、这事儿到底改变了什么
以前我们做回测,是假设驱动。先有一个想法,再去找数据验证。这很容易变成自我证明的闭环。
现在这套流程把它彻底倒过来了。你让数学先说话,让穷举结果替你提出假设,然后你再去审视这个假设是否符合市场常识。
RSI加布林带这种组合,如果不是机器扫出来,几个人会主动想到去测?随机指标单看很香,组合里却一塌糊涂,这种反直觉的结论,也只有在大规模扫描里才能浮出水面。
计算力让穷举变得廉价。廉价的穷举,让非直觉的策略有机会被发现。这才是AI给量化交易带来的真正礼物:不是替代你思考,而是扩展你思考的边界。
观点总结
传统回测像拿着手电筒找东西,光照到哪就只能看到哪。而批量穷举回测像打开全屋的灯,让所有信号同时显形,再用数学帮你筛选。这种方法最大的价值不是找到某个具体策略,而是彻底改变你寻找策略的起点,从”我觉得”变成”数据说”。
- 单指标回测容易陷入确认偏误,样本量不足时结论不可靠。
- 利用AI批量扫描技术指标,可快速定位真正有统计意义的信号。
- 扩展指标库至数百个,显著增加发现非直觉策略的概率。
- 双指标”与”逻辑组合能有效过滤噪音,提升信号质量。
- 最终必须穿透交易日志验证,数字好看不如逻辑过硬。
最后多说一句:方法归方法,敬畏归敬畏。回测是回测,实盘是实盘。
历史数据能告诉你过去发生了什么,但不能担保未来一定重演。任何策略在真正落地之前,都需要样本外测试和更严格的压力检验。别因为几张漂亮的曲线图就盲目乐观。我们用量化的目的,不是为了追求短期暴富,而是为了在这个充满噪音的市场里,用规则和纪律保护自己。
风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。
版权声明:本文为原创内容,转载请注明出处。
#量化交易 #AI回测 #技术指标 #策略挖掘 #期望收益 #自动化交易 #数据驱动 #特斯拉 #Python #交易系统 #Alpha挖掘 #金融科技
Be First to Comment